fielding_dissertation_ja
UNIVERSITY OF CALIFORNIA, IRVINE
Architectural Styles and the Design of Network-based Software Architectures
アーキテクチャスタイルとネットワークベースのソフトウェアアーキテクチャの設計
DISSERTATION
submitted in partial satisfaction of the requirements for the degree of DOCTOR OF PHILOSOPHY in Information and Computer Science by Roy Thomas Fielding
Dissertation Committee:
Professor Richard N. Taylor, Chair Professor Mark S. Ackerman Professor David S. Rosenblum
2000
献辞
私の両親、
ピート・フィールディングとキャスリーン・フィールディングに、
彼らの終わりのない励ましと忍耐のおかげで、これらすべてが可能になりました。
そしてまた、
ティム・バーナーズ=リーにも、
World Wide Webをオープンで協力的なプロジェクトにしてくれたことに感謝します。
人生とは何か? それは夜の蛍の瞬きである。 それは冬のバッファローの息遣いである。 それは草の上を駆け抜け、 夕日に消える小さな影である。 — クロウフット(1890年)、ブラックフット族の戦士であり演説者の最後の言葉。
ほとんど誰もが自然と調和していると感じる:海岸に打ち寄せる波の音を聞きながら、静かな湖のほとりで、草原の上で、風の吹きすさぶ荒野で。いつか、私たちが再び時の流れに逆らわない方法を学んだとき、私たちは自分の町についても同じように感じ、今日海辺を歩いたり、草原の長い草の上に横たわったりするのと同じほど、町の中で平和を感じるようになるだろう。 — クリストファー・アレグザンダー、『The Timeless Way of Building』(1979年)
iii
目次
序章 1
第1章: ソフトウェアアーキテクチャ 5
第2章: ネットワークベースのアプリケーションアーキテクチャ 24
第3章: ネットワークベースのアーキテクチャスタイル 38
- 3.1 分類方法論
- 3.2 データフロースタイル
- 3.3 レプリケーションスタイル
- 3.4 階層型スタイル
- 3.5 モバイルコードスタイル
- 3.6 ピアツーピアスタイル
- 3.7 制限事項
- 3.8 関連研究
- 3.9 まとめ
第4章: Webアーキテクチャの設計 67
第5章: 表現的状態転送 (REST) 76
第6章: 経験と評価 99
結論
参考文献
テーブル一覧
ページ
表3-1. ネットワークベースのハイパーメディアにおけるデータフロースタイルの評価 41
表3-2. ネットワークベースのハイパーメディアにおけるレプリケーションスタイルの評価 43
表3-3. ネットワークベースのハイパーメディアにおける階層スタイルの評価 45
表3-4. ネットワークベースのハイパーメディアにおけるモバイルコードスタイルの評価 51
表3-5. ネットワークベースのハイパーメディアにおけるピアツーピアスタイルの評価 55
表3-6. 評価のまとめ 65
表5-1. RESTデータ要素 88
表5-2. RESTコネクタ 93
表5-3. RESTコンポーネント 96
viii
謝辞
カリフォルニア大学アーバイン校(UCI)の教職員や学生の方々と、博士課程在籍中に共に働けたことは非常に光栄でした。この研究を成し遂げることができたのは、私が自分の研究関心を追求する自由を与えられたおかげであり、それは私の長年のアドバイザーであり委員会の議長を務めてくださったディック・テイラー氏の親切さと多大な指導によるものです。また、マーク・アッカーマン氏にも深く感謝しています。1993年に彼が担当した分散情報サービスの授業が、私をウェブ開発者コミュニティに導き、この論文で述べられているすべての設計作業につながったからです。同様に、デイヴィッド・ローゼンブラム氏のインターネット規模のソフトウェアアーキテクチャに関する研究が、私にハイパーメディアやアプリケーション層プロトコル設計だけでなく、アーキテクチャという視点で研究を考えるきっかけを与えてくれました。
ウェブのアーキテクチャスタイルは6年間にわたって繰り返し開発されましたが、特に1995年の最初の6ヶ月間に集中して進められました。それは、UCIの研究者、World Wide Web Consortium(W3C)のスタッフ、そしてInternet Engineering Taskforce(IETF)のHTTPおよびURIワーキンググループのエンジニアたちとの無数の議論に影響を受けています。特に、ティム・バーナーズ=リー、ヘンリック・フリステク・ニールセン、ダン・コノリー、デイヴ・ラゲット、ロヒット・カレ、ジム・ホワイトヘッド、ラリー・マシンター、ダン・ラリバートらに、WWWアーキテクチャの本質と目標についての多くの有意義な議論を感謝します。また、ケン・アンダーソン氏には、オープンハイパーテキストコミュニティへの洞察と、UCIにおけるハイパーメディア研究の道を切り開いてくれたことに感謝します。さらに、UCIのアーキテクチャ研究者仲間であるペイマン・オレイジー、ネノ・メドヴィドヴィック、ジェイソン・ロビンス、デイヴィッド・ヒルベルトにも感謝します。
ウェブアーキテクチャは、数十人のボランティアソフトウェア開発者の協力によって成り立っています。彼らの多くは、ウェブが商業的な現象になる前にその先駆者として貢献したにもかかわらず、正当な評価を受けることが少なかった。上記のW3Cの人々に加えて、1993年から1994年にかけてウェブの急速な成長を可能にしたサーバー開発者たちにも敬意を表したいと思います(私は、ブラウザよりも彼らの貢献が大きいと考えています)。その中には、ロブ・マクール(NCSA httpd)、アリ・ルオトネン(CERN httpd/proxy)、トニー・サンダース(Plexus)が含まれます。また、「ミスター・コンテンツ」ことケビン・ヒューズ氏にも感謝します。彼は、ハイパーテキスト以外の情報をウェブ上で表示する興味深い方法を最初に実装した人物です。初期のクライアント開発者たちにも感謝を捧げます:ニコラ・ペロー(ラインモード)、ペイ・ウェイ(Viola)、トニー・ジョンソン(Midas)、ルー・モントゥーリ(Lynx)、ビル・ペリー(W3)、そしてマーク・アンドリーセンとエリック・ビーナ(Mosaic for X)。最後に、私のlibwww-perlの共同作業者であるオスカー・ニールストラス、マルティン・コスター、ギスレ・アースに個人的な感謝を述べたいと思います。乾杯!
ix
現代のウェブアーキテクチャは、依然として単一の企業よりも個々のボランティアの仕事によって定義されています。その中でも特に重要なのは、Apacheソフトウェア財団のメンバーたちです。特に、ロバート・S・タウ氏には、Apache 1.0につながる非常に堅牢なシャンバラデザインと、望ましい(そして望ましくない)ウェブ拡張についての多くの議論に感謝します。また、ディーン・ゴーデット氏には、詳細なシステムパフォーマンス評価について、私が必要とする以上のことを教えてくれたことに感謝します。さらに、アレクセイ・コスート氏には、HTTP/1.1の大部分をApacheに初めて実装してくれたことに感謝します。その他のApache Groupの創設者であるブライアン・ベーレンドルフ、ロブ・ハーティル、デイヴィッド・ロビンソン、クリフ・スコルニック、ランディ・ターブッシュ、アンドリュー・ウィルソンにも、私たち全員が誇りに思えるコミュニティを築き、世界をもう一度変えてくれたことに感謝します。
また、eBuiltのすべての人々にも感謝します。特に、4人の技術創設者であるジョー・リンジー、フィル・リンジー、ジム・ヘイズ、ジョー・マンナには、エンジニアリングを楽しくする文化を創り出し(そして守ってくれた)ことに感謝します。また、マイク・デューイ、ジェフ・レナードソン、チャーリー・バンテン、テッド・ラヴォイにも、楽しみながらお金を稼ぐことを可能にしてくれたことに感謝します。そして、特に…
リンダ・デイリング、私たち全員を一つにまとめてくれたことに感謝します。
エンデバーズ・テクノロジーのチーム、グレッグ・ボルサー、クレイ・カバー、アート・ヒトミ、ピーター・カマーにも感謝と幸運を祈ります。最後に、この論文を執筆する際にインスピレーションを与えてくれた3人のミューズ、ローラ、ニッキー、リンに感謝します。
私の論文研究の大部分は、国防高等研究計画局(DARPA)および空軍研究研究所、空軍器材コマンド、米国空軍によって、契約番号F30602-97-2-0021の下で支援されました。米国政府は、著作権の注記に関わらず、政府の目的のために複製や配布を行う権限を有しています。ここに記載された見解や結論は著者らのものであり、必ずしも国防高等研究計画局、空軍研究研究所、または米国政府の公式な方針や支持を表すものではありません。
x
履歴書
ロイ・トーマス・フィールディング
学歴
博士(Ph.D.) (2000年)
カリフォルニア大学アーバイン校
情報計算科学
ソフトウェア研究所
指導教授: Dr. Richard N. Taylor
博士論文: アーキテクチャスタイルとネットワークベースのソフトウェアアーキテクチャの設計
修士(M.S.) (1993年)
カリフォルニア大学アーバイン校
情報計算科学
専攻: ソフトウェア
学士(B.S.) (1988年)
カリフォルニア大学アーバイン校
情報計算科学
職務経験
12/99 - チーフサイエンティスト、eBuilt, Inc.、カリフォルニア州アーバイン
3/99 - 議長、The Apache Software Foundation
4/92 - 12/99 大学院研究員、ソフトウェア研究所
カリフォルニア大学アーバイン校
6/95 - 9/95 客員研究員、World Wide Web Consortium (W3C)
マサチューセッツ工科大学コンピュータ科学研究所、マサチューセッツ州ケンブリッジ
9/91 - 3/92 ティーチングアシスタント
ICS 121 - ソフトウェア工学入門
ICS 125A - ソフトウェア工学プロジェクト
カリフォルニア大学アーバイン校
11/89 - 6/91 ソフトウェアエンジニア
ADC Kentrox, Inc.、オレゴン州ポートランド
7/88 - 8/89 プロフェッショナルスタッフ(ソフトウェアエンジニア)
PRC Public Management Services, Inc.、カリフォルニア州サンフランシスコ
10/86 - 6/88 プログラマー/アナリスト
Megadyne Information Systems, Inc.、カリフォルニア州サンタアナ
6/84 - 9/86 プログラマー/アナリスト
TRANSMAX, Inc.、カリフォルニア州サンタアナ
xi
業績
査読付きジャーナル論文
[1] R. T. Fielding, E. J. Whitehead, Jr., K. M. Anderson, G. A. Bolcer, P. Oreizy, および
R. N. Taylor. Webベースの複雑な情報製品の開発.
Communications of the ACM , 41(8), 1998年8月, pp. 84-92.
[2] R. T. Fielding. 分散型ハイパーテキスト情報基盤の維持: MOMspiderのWebへようこそ.
Computer Networks and ISDN Systems , 27(2), 1994年11月,
pp. 193-204. (査読者による特別選定後の[7]の改訂版.)
査読付き会議論文
[3] R. T. Fielding および R. N. Taylor. 現代のWebアーキテクチャの原則に基づく設計.
2000年国際ソフトウェア工学会議 (ICSE 2000) 議事録 , アイルランド、リムリック, 2000年6月, pp. 407-416.
[4] A. Mockus, R. T. Fielding, および J. Herbsleb. オープンソースソフトウェア開発の事例研究: Apacheサーバー.
2000年国際ソフトウェア工学会議 (ICSE 2000) 議事録 , アイルランド、リムリック, 2000年6月, pp.
263-272.
[5] E. J. Whitehead, Jr., R. T. Fielding, および K. M. Anderson. WWWとリンクサーバー技術の融合: 一つのアプローチ.
第2回オープンハイパーメディアシステムワークショップ, Hypertext’96 , ワシントンD.C., 1996年3月, pp. 81-86.
[6] M. S. Ackerman および R. T. Fielding. デジタルライブラリにおけるコレクションの維持.
デジタルライブラリ ’95 議事録 , テキサス州オースティン, 1995年6月, pp. 39-48.
[7] R. T. Fielding. 分散型ハイパーテキスト情報基盤の維持: MOMspiderのWebへようこそ.
第1回国際World Wide Web会議議事録 , スイス、ジュネーブ, 1994年5月, pp. 147-156.
業界標準
[8] R. T. Fielding, J. Gettys, J. C. Mogul, H. F. Nielsen, L. Masinter, P. Leach, および
T. Berners-Lee. ハイパーテキスト転送プロトコル — HTTP/1.1.
インターネットドラフト標準 RFC 2616 , 1999年6月. [RFC 2068 を廃止, 1997年1月.]
[9] T. Berners-Lee, R. T. Fielding, および L. Masinter. 統一リソース識別子
(URI): 汎用構文. インターネットドラフト標準 RFC 2396 , 1998年8月.
[10] J. Mogul, R. T. Fielding, J. Gettys, および H. F. Frystyk. HTTPバージョン番号の使用と解釈.
インターネット情報 RFC 2145 , 1997年5月.
[11] T. Berners-Lee, R. T. Fielding, および H. F. Nielsen. ハイパーテキスト転送プロトコル —
HTTP/1.0. インターネット情報 RFC 1945 , 1996年5月.
[12] R. T. Fielding. 相対的な統一リソースロケーター.
インターネット提案標準 RFC 1808 , 1995年6月.
xii
業界記事
[13] R. T. Fielding. Apacheの成功の秘訣.
Linux Magazine , 1(2), 1999年6月, pp. 29-71.
[14] R. T. Fielding. Apacheプロジェクトにおける共有リーダーシップ.
Communications of the ACM , 42(4), 1999年4月, pp. 42-43.
[15] R. T. Fielding および G. E. Kaiser. Apache HTTPサーバープロジェクト.
IEEE Internet Computing , 1(4), 1997年7月-8月, pp. 88-90.
非査読付き出版物
[16] R. T. Fielding. ネットワークベースアプリケーションのためのアーキテクチャスタイル. フェーズII
調査論文、情報とコンピュータサイエンス学部、カリフォルニア大学アーバイン校, 1999年7月.
[17] J. Grudin および R. T. Fielding. 設計方法とプロセスに関するワーキンググループ.
ICSE’94 Workshop on SE-HCI: Joint Research Issues の議事録、ソレント、イタリア、1994年5月。「Software Engineering and Human-Computer Interaction」としてSpringer-Verlag LNCS、vol. 896、1995年、pp. 4-8に掲載。
[18] R. T. Fielding. Conditional GET Proposal for HTTP Caching. WWW上で公開、1994年1月。
公開されたソフトウェアパッケージ
[19] Apache httpd。Apache HTTPサーバーは、2000年7月時点で全世界の65%以上の公開インターネットサイトで使用されている、世界で最も人気のあるWebサーバーソフトウェアです。
[20] libwww-perl。Perl4パッケージのライブラリで、World Wide Webへのシンプルで一貫したプログラミングインターフェースを提供します。
[21] Onions。Ada95パッケージのライブラリで、ネットワークおよびファイルシステムI/Oのための効率的なスタック可能なストリーム機能を提供します。
[22] MOMspider。MOMspiderは、分散ハイパーテキスト情報構造のマルチオーナー維持を提供するためのウェブロボットです。
[23] wwwstat。WWW httpdサーバーのアクセスログを検索および要約し、他のウェブマスタータスクを支援するためのユーティリティのセットです。
公式プレゼンテーション
[1] State of Apache。O’Reillyオープンソースソフトウェア会議、モントレー、カリフォルニア、2000年7月。
[2] Principled Design of the Modern Web Architecture。2000年国際ソフトウェアエンジニアリング会議、リムリック、アイルランド、2000年6月。
[3] HTTP and Apache。ApacheCon 2000、オーランド、フロリダ、2000年3月。
xiii
[4] Human Communication and the Design of the Modern Web Architecture。WebNetワールドカンファレンス on the WWW and the Internet (WebNet 99)、ホノルル、ハワイ、1999年10月。
[5] The Apache Software Foundation。Computer & Communications Industry Association、秋のメンバー会議、ダラス、テキサス、1999年9月。
[6] Uniform Resource Identifiers。The Workshop on Internet-scale Technology (TWIST 99)、アーバイン、カリフォルニア、1999年8月。
[7] Apache: Past, Present, and Future。Web Design World、シアトル、ワシントン、1999年7月。
[8] Progress Report on Apache。ZDオープンソースフォーラム、オースティン、テキサス、1999年6月。
[9] Open Source, Apache-style: Lessons Learned from Collaborative Software Development。Second Open Source and Community Licensing Summit、サンノゼ、カリフォルニア、1999年3月。
[10] The Apache HTTP Server Project: Lessons Learned from Collaborative Software. AT&T Labs — Research、フォルサムパーク、ニュージャージー、1998年10月。
[11] Collaborative Software Development: Joining the Apache Project。ApacheCon ‘98、サンフランシスコ、カリフォルニア、1998年10月。
[12] Representational State Transfer: An Architectural Style for Distributed Hypermedia Interaction。Microsoft Research、レドモンド、ワシントン、1998年5月。
[13] The Apache Group: A Case Study of Internet Collaboration and Virtual Communities。UC Irvine Social Sciences WWW Seminar、アーバイン、カリフォルニア、1997年5月。
[14] WebSoft: Building a Global Software Engineering Environment。Workshop on Software Engineering (on) the World Wide Web、1997年国際ソフトウェアエンジニアリング会議 (ICSE 97)、ボストン、マサチューセッツ、1997年5月。
[15] Evolution of the Hypertext Transfer Protocol。ICS Research Symposium、アーバイン、カリフォルニア、1997年1月。
[16] World Wide Web Infrastructure and Evolution。IRUS SETT Symposium on WIRED: World Wide Web and the Internet、アーバイン、カリフォルニア、1996年5月。
[17] HTTP Caching。第5回国際World Wide Web会議 (WWW5)、パリ、フランス、1996年5月。
[18] The Importance of World Wide Web Infrastructure。California Software Symposium (CSS ‘96)、ロサンゼルス、カリフォルニア、1996年4月。
[19] World Wide Web Software: An Insider’s View。IRUS Bay Area Roundtable (BART)、パロアルト、カリフォルニア、1996年1月。
[20] libwww-Perl4 and libwww-Ada95。第4回国際World Wide Web会議、ボストン、マサチューセッツ、1995年12月。
[21] Hypertext Transfer Protocol — HTTP/1.x。第4回国際World Wide Web会議、ボストン、マサチューセッツ、1995年12月。
xiv
[22] Hypertext Transfer Protocol — HTTP/1.x。HTTP Working Group、第34回Internet Engineering Taskforce会議、ダラス、テキサス、1995年12月。
[23] Hypertext Transfer Protocol — HTTP/1.0 and HTTP/1.1。HTTP Working Group、第32回Internet Engineering Taskforce会議、ダンバース、マサチューセッツ、1995年4月。
[24] WWW Developer Starter Kits for Perl. WebWorld Conference, オーランド, FL, 1995年1月、およびサンタクララ, CA, 1995年4月.
[25] Relative Uniform Resource Locators. URI Working Group, 第31回インターネットエンジニアリングタスクフォース会議, サンノゼ, CA, 1994年12月.
[26] Hypertext Transfer Protocol — HTTP/1.0. HTTP BOF, 第31回インターネットエンジニアリングタスクフォース会議, サンノゼ, CA, 1994年12月.
[27] Behind the Curtains: How the Web was/is/will be created. UC Irvine 社会科学ワールドワイドウェブセミナー, アーバイン, CA, 1995年10月.
[28] Maintaining Distributed Hypertext Infostructures: Welcome to MOMspider’s Web. 第1回国際ワールドワイドウェブ会議, ジュネーブ, スイス, 1994年5月.
専門活動
- Webmaster, 1997年国際ソフトウェアエンジニアリング会議 (ICSE’97), ボストン, 1997年5月.
- HTTPセッション議長, 第5回国際ワールドワイドウェブ会議 (WWW5), パリ, フランス, 1996年5月.
- Birds-of-a-Feather議長およびセッション議長, 第4回国際ワールドワイドウェブ会議 (WWW4), ボストン, 1995年12月.
- 学生ボランティア, 第17回国際ソフトウェアエンジニアリング会議 (ICSE 17), シアトル, 1995年6月.
- 学生ボランティア, 第2回国際ワールドワイドウェブ会議 (WWW2), シカゴ, 1994年10月.
- 学生ボランティア, 第16回国際ソフトウェアエンジニアリング会議 (ICSE 16), ソレント, イタリア, 1994年4月.
- 共同設立者およびメンバー, The Apache Group, 1995年〜現在.
- 創設者およびチーフアーキテクト, libwww-perl 共同プロジェクト, 1994-1995年.
- ICS代表, Associated Graduate Students Council, 1994-1995年.
専門協会
- The Apache Software Foundation
- コンピューティング機械学会 (ACM)
- ACMソフトウェアエンジニアリング特別関心グループ (SIGSOFT),
データ通信特別関心グループ (SIGCOMM), グループウェア特別関心グループ (SIGGROUP)
名誉、賞、フェローシップ
2000年 Appaloosa Award for Vision, O’Reilly Open Source 2000
2000年 Outstanding Graduate Student, UCI Alumni Association
1999年 ACMソフトウェアシステム賞
1999年 TR100: トップ100若きイノベーター, MIT Technology Review
1991年 カリフォルニア大学 Regent’s Fellowship
1988年 Golden Key National Honor Society
1987年 Dean’s Honor List
論文の要旨
ネットワークベースのソフトウェアアーキテクチャの設計におけるアーキテクチャスタイル
著者
ロイ・トーマス・フィールディング
情報とコンピュータ科学の博士号
カリフォルニア大学アーバイン校、2000年
リチャード・N・テイラー教授、指導教授
ワールドワイドウェブは、そのソフトウェアアーキテクチャがインターネット規模の分散ハイパーメディアシステムのニーズを満たすように設計されていることから、大きな成功を収めています。ウェブは、過去10年間にわたって、そのアーキテクチャを定義する標準の一連の変更を通じて反復的に開発されてきました。ウェブの改良が必要な側面を特定し、望ましくない変更を回避するために、モダンなウェブアーキテクチャのモデルが必要であり、その設計、定義、展開を導く必要がありました。ソフトウェアアーキテクチャ研究は、システムをどのように最適に分割するか、コンポーネントがどのように互いを識別し通信するか、情報がどのように伝達されるか、システムの要素がどのように独立して進化できるか、そしてこれらすべてを形式的および非形式的な記法で記述する方法を探究します。私の研究は、ネットワークベースのアプリケーションソフトウェアのアーキテクチャ設計を理解し評価したいという欲求に動機づけられており、それによって、アーキテクチャに望まれる機能、性能、社会的特性を得るための基本原理的なアーキテクチャ制約の使用を目指しています。アーキテクチャスタイルとは、名前付けされた、調整された一連のアーキテクチャ制約です。
xvii
この論文は、アーキテクチャスタイルを通じてソフトウェアアーキテクチャを理解するためのフレームワークを定義し、スタイルがネットワークベースのアプリケーションソフトウェアのアーキテクチャ設計を導くためにどのように使用できるかを示しています。ネットワークベースアプリケーションのアーキテクチャスタイルの調査を使用して、これらのスタイルを、分散ハイパーメディアのアーキテクチャに誘発するアーキテクチャ特性に従って分類します。次に、Representational State Transfer(REST)アーキテクチャスタイルを紹介し、RESTがモダンなウェブのアーキテクチャの設計と開発を導くためにどのように使用されてきたかを説明します。RESTは、コンポーネント間相互作用のスケーラビリティ、インターフェースの汎用性、コンポーネントの独立した展開、相互作用の待ち時間を短縮し、セキュリティを強化し、レガシーシステムをカプセル化する中間コンポーネントを強調しています。RESTを導くソフトウェアエンジニアリングの原則と、それらの原則を保持するために選択された相互作用制約について説明し、それらを他のアーキテクチャスタイルの制約と対比します。最後に、RESTをハイパーテキスト転送プロトコル(HTTP)と統一資源識別子(URI)標準の設計に適用したこと、およびそれらがウェブクライアントおよびサーバーソフトウェアに展開されたことから得られた教訓について説明します。
序章
すみません…「ナイフ」と言いましたか?
— シティ・ジェント #1 (マイケル・パーリン), 『建築家のスケッチ』 [111]
ペリーとウルフ [105] が予測したように、ソフトウェアアーキテクチャは1990年代のソフトウェアエンジニアリング研究の焦点となってきました。現代のソフトウェアシステムの複雑さは、実装が独立したコンポーネントに分割され、それらが通信して所望のタスクを実行するコンポーネント化されたシステムに重点を置く必要性を生み出しました。ソフトウェアアーキテクチャ研究は、システムをどのように最適に分割するか、コンポーネントが互いにどのように識別し通信するか、情報がどのように伝達されるか、システムの要素がどのように独立して進化できるか、そして上記のすべてを形式記法や非公式記法でどのように記述するかについての方法を調査しています。
優れたアーキテクチャは真空の中で生まれるものではありません。アーキテクチャレベルのすべての設計決定は、設計されているシステムの機能、振る舞い、社会的要件の文脈の中で行われなければなりません。これは、ソフトウェアアーキテクチャと伝統的な建築の分野の両方に等しく適用される原則です。「形は機能に従う」という指針は、数百年にわたる失敗した建築プロジェクトの経験から導かれたものですが、ソフトウェアの実践者によってしばしば無視されています。上記のモンティ・パイソンのスケッチの中の面白い部分は、都市のアパートブロックを設計するという目標に直面した建築家が、現代の屠殺場のすべてのコンポーネントを持つ建物のデザインを提示するという不合理な考えです。それはおそらくこれまでに考案された中で最高の屠殺場デザインかもしれませんが、それでも回転するナイフが並ぶ廊下を通って運ばれる将来のテナントにとってはほとんど慰めにはならないでしょう。
建築家のスケッチ の誇張はばかばかしく見えるかもしれませんが、ソフトウェアプロジェクトが最新のアーキテクチャデザインの流行を取り入れて開始され、システム要件がそのようなアーキテクチャを必要とするかどうかが後になって発見されることがどれだけ頻繁にあるかを考えてみてください。バズワードによる設計はよくある出来事です。少なくともソフトウェア業界内でのこのような行動の一部は、与えられたアーキテクチャ制約のセットがなぜ有用であるかを理解していないことに起因しています。言い換えれば、優れたソフトウェアアーキテクチャの背後にある理由は、それらのアーキテクチャが再利用のために選択された際に設計者にとって明白ではないのです。
この論文は、コンピュータサイエンスの2つの研究分野のフロンティアであるソフトウェアとネットワーキングの交差点を探求します。ソフトウェア研究は長い間、ソフトウェアデザインの分類とデザイン方法論の開発に関心を向けてきましたが、さまざまなデザイン選択がシステムの振る舞いに及ぼす影響を客観的に評価することはほとんどできませんでした。一方、ネットワーキング研究は、システム間の一般的な通信行動の詳細と特定の通信技術の性能向上に焦点を当てており、しばしばアプリケーションの相互作用スタイルを変更することがその相互作用に使用される通信プロトコル以上に性能に影響を与える可能性があるという事実を無視しています。私の研究は、アーキテクチャ制約を原理的に使用してネットワークベースのアプリケーションソフトウェアのアーキテクチャデザインを理解し評価し、それによってアーキテクチャに望まれる機能的、性能的、社会的特性を得るという願望に動機付けられています。名前が与えられると、調整された一連のアーキテクチャ制約はアーキテクチャスタイルとなります。
この論文の最初の3つの章は、アーキテクチャスタイルを通じてソフトウェアアーキテクチャを理解するためのフレームワークを定義し、スタイルがどのようにネットワークベースのアプリケーションソフトウェアのアーキテクチャデザインを導くために使用できるかを示しています。一般的なアーキテクチャスタイルは、ネットワークベースのハイパーメディアのアーキテクチャに適用された際に誘導するアーキテクチャ特性に従って調査および分類されています。この分類は、初期のWorld Wide Webのアーキテクチャを改善するために使用できる一連のアーキテクチャ制約を特定するために使用されます。
ウェブのアーキテクチャ設計には、その要求事項を理解することが必要です。第4章で詳しく説明するように、ウェブは インターネット規模 の分散型ハイパーメディアシステムとして設計されており、これは単なる地理的な分散以上の意味を持ちます。インターネットは、組織の境界を越えた情報ネットワークの相互接続を実現するものです。情報サービスの提供者は、無秩序なスケーラビリティの要求やソフトウェアコンポーネントの独立した展開に対応できる必要があります。分散型ハイパーメディアは、リモートサイトから取得した情報のプレゼンテーション内にアクションコントロールを埋め込むことで、サービスにアクセスするための統一された手段を提供します。したがって、ウェブのアーキテクチャは、高いレイテンシのネットワークや複数の信頼境界を越えて大きな粒度のデータオブジェクトを通信するという文脈で設計される必要があります。
第5章では、分散型ハイパーメディアシステムのためのRepresentational State Transfer(REST)アーキテクチャスタイルを紹介し、詳細に説明します。RESTは、コンポーネント間の相互作用のスケーラビリティ、インターフェースの汎用性、コンポーネントの独立した展開、相互作用のレイテンシを削減する仲介コンポーネント、セキュリティの実施、レガシーシステムのカプセル化を強調するための一連のアーキテクチャ制約を提供します。私は、RESTを導くソフトウェアエンジニアリングの原則と、それらの原則を維持するために選ばれた相互作用の制約について説明し、他のアーキテクチャスタイルの制約と比較します。
過去6年間、RESTアーキテクチャスタイルは、現代のウェブのアーキテクチャ設計と開発を導くために使用されてきました。これは、第6章で紹介されています。この作業は、ハイパーテキスト転送プロトコル(HTTP)と統一資源識別子(URI)のインターネット標準の執筆とともに行われました。これら2つの仕様は、ウェブ上のすべてのコンポーネント間相互作用で使用される汎用インターフェースを定義しています。
ほとんどの現実世界のシステムと同様に、展開されたウェブアーキテクチャのすべてのコンポーネントが、そのアーキテクチャ設計に存在するすべての制約に従っているわけではありません。RESTは、アーキテクチャの改善を定義する手段として、またアーキテクチャのミスマッチを特定するために使用されてきました。ミスマッチは、無知や見落としのために、アーキテクチャ制約に違反するソフトウェア実装が展開された場合に発生します。ミスマッチは一般的に避けられませんが、標準化される前に特定することが可能です。第6章では、現代のウェブアーキテクチャ内のいくつかのミスマッチと、それらがなぜ発生したのか、そしてRESTからどのように逸脱しているのかについての分析をまとめています。
要約すると、この論文は、情報および計算機科学分野におけるソフトウェア研究に以下の貢献をしています:
- アーキテクチャスタイルを通じてソフトウェアアーキテクチャを理解するためのフレームワーク。これには、ソフトウェアアーキテクチャを記述するための一貫した用語集が含まれます。
- ネットワークベースのアプリケーションソフトウェアのアーキテクチャスタイルの分類。これらは、分散型ハイパーメディアシステムのアーキテクチャに適用された場合に誘発されるアーキテクチャ的特性によって分類されます。
- 分散型ハイパーメディアシステムのための新しいアーキテクチャスタイルであるREST。
- 現代のワールドワイドウェブのアーキテクチャ設計と展開におけるRESTアーキテクチャスタイルの適用と評価。
第1章
ソフトウェアアーキテクチャ
ソフトウェアアーキテクチャは研究分野として関心を集めているにもかかわらず、研究者の間ではアーキテクチャの定義に何を含めるべきかについてほとんど合意が得られていません。多くの場合、これにより、過去の研究で重要なアーキテクチャ設計の側面が見落とされてきました。この章では、文献内の既存の定義と、ネットワークベースのアプリケーションアーキテクチャに関する私自身の洞察に基づいて、ソフトウェアアーキテクチャの一貫した用語を定義します。参照を容易にするためにボックス内に強調表示された各定義は、関連する研究からどのように導き出されたか、またはそれと比較してどのようなものかについての議論が続きます。
1.1 ランタイムの抽象化
ソフトウェアアーキテクチャの中核には、抽象化の原則があります。つまり、システムの詳細をカプセル化することで隠し、その特性をよりよく識別し維持することです [117]。複雑なシステムには多くのレベルの抽象化があり、それぞれに独自のアーキテクチャがあります。アーキテクチャとは、そのレベルでのシステムの動作の抽象化を表し、そのレベルでの他の要素に提供する抽象インターフェースによってアーキテクチャ要素が定義されます [9]。各要素の中には、親要素の抽象インターフェースが表す動作を実装するサブ要素のシステムを定義する別のアーキテクチャが見つかることがあります。
ソフトウェアアーキテクチャは、ソフトウェアシステムのランタイム要素を、その操作の特定の段階での抽象化したものです。システムは多くのレベルの抽象化と多くの操作段階で構成されることがあり、それぞれに独自のソフトウェアアーキテクチャを持ちます。
このアーキテクチャの再帰は、最も基本的なシステム要素まで続きます。つまり、それ以上抽象化できない要素です。
アーキテクチャのレベルに加えて、ソフトウェアシステムにはしばしば複数の操作段階があります。例えば、起動、初期化、通常処理、再初期化、シャットダウンなどです。各操作段階には独自のアーキテクチャがあります。たとえば、設定ファイルは起動段階ではデータ要素として扱われますが、通常処理中ではアーキテクチャ要素とは見なされません。なぜなら、その時点ではその情報はすでにシステム全体に分散しているからです。実際、その設定ファイルが通常処理のアーキテクチャを定義しているかもしれません。システムアーキテクチャの全体的な記述は、各段階でのシステムアーキテクチャの動作だけでなく、段階間の遷移のアーキテクチャも説明できなければなりません。
PerryとWolf [105]は、処理要素を「データの変換器」と定義し、Shawら [118]はコンポーネントを「計算と状態の場」と説明しています。これはShawとClements [122]でさらに明確化されています。「コンポーネントとは、ランタイムで何らかの機能を実行するソフトウェアの単位です。例としては、プログラム、オブジェクト、プロセス、フィルタなどがあります。」これは、ソフトウェアアーキテクチャと通常ソフトウェア構造と呼ばれるものとの重要な区別を提起します。前者はソフトウェアシステムのランタイム動作の抽象化であり、後者は静的ソフトウェアソースコードの特性です。ソースコードのモジュール構造が実行中のシステム内の動作の分解と一致することには利点がありますが、独立したソフトウェアコンポーネントが同じコードの一部(例えば、共有ライブラリ)を使用して実装されることにも利点があります。私たちは、特定のコンポーネントの実装に依存しないように、ソフトウェアアーキテクチャのビューをソースコードのビューから分離しています。したがって、アーキテクチャ設計とソースコードの構造設計は密接に関連していますが、別々の設計活動です。残念ながら、ソフトウェアアーキテクチャの説明の中にはこの区別をしないものもあります(例:[9])。
1.2 要素
ソフトウェアアーキテクチャの範囲と知的基盤に関する包括的な考察は、PerryとWolf [105] に見ることができます。彼らは、ソフトウェアアーキテクチャを特定の形式を持ち、根拠によって説明される一連のアーキテクチャ要素の集合として定義するモデルを提示しています。アーキテクチャ要素には、処理要素、データ要素、接続要素が含まれます。形式は、要素の特性と要素間の関係、つまり要素に対する制約によって定義されます。根拠は、アーキテクチャスタイルの選択、要素の選択、および形式の選択の動機を捉えることで、アーキテクチャの基礎を提供します。
私のソフトウェアアーキテクチャの定義は、PerryとWolf [105] のモデル内の定義を拡張したものですが、根拠を除外しています。根拠はソフトウェアアーキテクチャの研究、特にアーキテクチャ記述において重要な側面ですが、それをソフトウェアアーキテクチャの定義に含めることは、設計ドキュメントが実行時システムの一部であることを意味します。根拠の有無はアーキテクチャの進化に影響を与える可能性がありますが、一度構成されると、アーキテクチャはその存在理由から独立しています。リフレクティブシステム [80] は過去のパフォーマンスの特性を使用して将来の動作を変更することができますが、その際にそれらのアーキテクチャ内に根拠を含めるのではなく、別の低レベルのアーキテクチャに置き換えています。
例として、建物の設計図や設計計画が焼失した場合に何が起こるかを考えてみましょう。建物はすぐに崩壊するでしょうか?いいえ、壁が屋根の重量を支える特性はそのまま残っているためです。アーキテクチャは、設計上、システム要件を満たすか超える一連の特性を持っています。それらの特性を無視すると、後々の変更がアーキテクチャに違反する可能性があります。ちょうど、荷重を支える壁を大きな窓枠に置き換えることが建物の構造的安定性を損なうのと同じです。したがって、根拠の代わりに、私たちのソフトウェアアーキテクチャの定義にはアーキテクチャ特性が含まれます。根拠はそれらの特性を説明し、根拠の欠如は時間の経過とともにアーキテクチャの徐々の劣化や衰退を引き起こす可能性がありますが、根拠自体はアーキテクチャの一部ではありません。
PerryとWolf [105] のモデルの重要な特徴は、さまざまな要素タイプの区別です。処理要素はデータに対して変換を実行する要素、データ要素は使用および変換される情報を含む要素、接続要素はアーキテクチャの異なる部分を結びつける接着剤です。私は、より一般的な用語であるコンポーネントとコネクタをそれぞれ処理要素と接続要素を指すために使用します。
GarlanとShaw [53] は、システムのアーキテクチャを計算コンポーネントの集合と、これらのコンポーネント間の相互作用(コネクタ)の記述として説明しています。このモデルはShawら [118] でさらに拡張されています:ソフトウェアシステムのアーキテクチャは、コンポーネントとそれらのコンポーネント間の相互作用の観点からそのシステムを定義します。システムの構造とトポロジーを指定することに加えて、アーキテクチャはシステム要件と構築されたシステムの要素との意図された対応関係を示します。この定義のさらなる詳細はShawとGarlan [121] に見ることができます。
Shawら [118] のモデルで驚くべきことは、ソフトウェアのアーキテクチャをソフトウェア内に存在するものとして定義するのではなく、ソフトウェアのアーキテクチャの記述をあたかもそれがアーキテクチャであるかのように定義している点です。その過程で、ソフトウェア
アーキテクチャ全体は、ほとんどの非公式なアーキテクチャ図で一般的に見られるものに還元されます。つまり、ボックス(コンポーネント)と線(コネクタ)です。データ要素や、実際のソフトウェアアーキテクチャの多くの動的な側面は無視されます。このようなモデルは、ネットワークベースのソフトウェアアーキテクチャを適切に記述することができません。なぜなら、システム内のデータ要素の性質、位置、移動がしばしばシステムの挙動を決定する最も重要な要因だからです。
1.2.1 コンポーネント
コンポーネントは、ソフトウェアアーキテクチャの中で最も容易に認識される側面です。PerryとWolf [105] の処理要素は、データ要素に対して変換を提供するコンポーネントとして定義されています。GarlanとShaw [53] は、コンポーネントを単に計算を実行する要素として説明しています。私たちの定義は、コンポーネントとコネクタ内のソフトウェアを区別することをより正確にしようとしています。 コンポーネントは、ソフトウェア命令と内部状態の抽象的な単位であり、そのインターフェースを介してデータの変換を提供します。変換の例には、
コンポーネントは、ソフトウェア命令と内部状態の抽象的な単位であり、そのインターフェースを介してデータの変換を提供します。
二次ストレージからメモリへのロード、何らかの計算の実行、異なる形式への変換、他のデータとのカプセル化などが含まれます。各コンポーネントの挙動は、その挙動が他のコンポーネントの観点から観察または識別できる限り、アーキテクチャの一部です [9]。言い換えれば、コンポーネントはそのインターフェースと、他のコンポーネントに提供するサービスによって定義され、インターフェースの背後にある実装によって定義されるわけではありません。Parnas [101] はこれを、他のアーキテクチャ要素がコンポーネントについて行うことができる仮定のセットとして定義するでしょう。
1.2.2 コネクタ
PerryとWolf [105] は、接続要素を曖昧に、アーキテクチャのさまざまな部分を結びつける接着剤として説明しています。ShawとClements [122] は、より正確な定義を提供しています。コネクタは、コンポーネント間の通信、調整、または協力を仲介する抽象的なメカニズムです。例としては、共有表現、リモートプロシージャコール、メッセージパッシングプロトコル、データストリームなどがあります。おそらく、コネクタを理解する最良の方法は、コンポーネントと対比することです。コネクタは、データ要素を変更せずに、あるインターフェースから別のインターフェースに転送することで、コンポーネント間の通信を可能にします。内部的には、コネクタは、データを転送用に変換し、転送を実行し、配信のために変換を逆にするコンポーネントのサブシステムで構成されているかもしれません。しかし、アーキテクチャによって捕捉される外部の挙動の抽象化は、これらの詳細を無視します。対照的に、コンポーネントは、外部の観点からデータを変換するかもしれませんが、必ずしもそうとは限りません。
コネクタは、コンポーネント間の通信、調整、または協力を仲介する抽象的なメカニズムです。
1.2.3 データ
前述のように、データ要素の存在は、PerryとWolf [105] によって定義されたソフトウェアアーキテクチャのモデルと、ソフトウェアアーキテクチャとラベル付けされた研究の多くで使用されるモデルとの最も重要な違いです [1, 5, 9, 53, 56, 117-122, 128]。Boasson [24] は、現在のソフトウェアアーキテクチャ研究がコンポーネント構造とアーキテクチャ開発ツールに重点を置いていることを批判し、データ中心のアーキテクチャモデリングにもっと焦点を当てるべきだと提案しています。Jackson [67] も同様のコメントをしています。 データは、コンポーネントから転送される、またはコンポーネントによって受信される情報の要素です。例としては、バイトシーケンス、メッセージ、マーシャリングされたパラメータ、シリアライズされたオブジェクトなどが含まれますが、コンポーネント内に永続的に存在するか、隠されている情報は含まれません。アーキテクチャの観点から見ると、「ファイル」は、ファイルシステムコンポーネントがそのインターフェースで受信した「ファイル名」データから、内部に隠されたバイトシーケンスに変換するものかもしれません。
ストレージシステム。コンポーネントは、クロックやセンサーのソフトウェアカプセル化の場合のように、データを生成することもあります。
ネットワークベースのアプリケーションアーキテクチャ内のデータ要素の性質は、特定のアーキテクチャスタイルが適切かどうかをしばしば決定します。これは、モバイルコード設計パラダイムの比較において特に顕著です[50]。そこでは、コンポーネントと直接やり取りするか、コンポーネントをデータ要素に変換し、ネットワークを介して転送し、その後ローカルでやり取りできるコンポーネントに戻すかを選択する必要があります。
アーキテクチャレベルでデータ要素を考慮せずに、そのようなアーキテクチャを評価することは不可能です。
A datum is an element of information that is transferred from a
component, or received by a component, via a connector.
1.3 構成
Abowdら[1]は、アーキテクチャ記述を、3つの基本的な構文的クラスに基づいてシステムを記述するものと定義しています。すなわち、計算の場となるコンポーネント、コンポーネント間の相互作用を定義するコネクタ、そして相互作用するコンポーネントとコネクタの集合である構成(configurations)です。様々なスタイル固有の具体的な記法を使用して、これらを視覚的に表現したり、合法的な計算と相互作用の記述を容易にしたり、望ましいシステムの集合を制約したりすることができます。
厳密に言えば、構成はコンポーネント間の相互作用に対する特定の制約の集合と同等と考えることができます。例えば、PerryとWolf[105]は、アーキテクチャ形式の関係の定義にトポロジーを含めています。しかし、アクティブなトポロジーをより一般的な制約から分離することで、アーキテクチャはアクティブな構成とすべての合法な構成の潜在領域をより簡単に区別できるようになります。アーキテクチャ記述言語内で構成を区別するための追加の根拠は、MedvidovicとTaylor[86]で提示されています。
1.4 プロパティ
ソフトウェアアーキテクチャのアーキテクチャプロパティのセットは、システム内のコンポーネント、コネクタ、およびデータの選択と配置から導かれるすべてのプロパティを含みます。例としては、システムによって達成される機能的なプロパティと、進化の容易さ、コンポーネントの再利用性、効率性、動的な拡張性などの非機能的なプロパティ(しばしば品質属性と呼ばれる [9])が挙げられます。
構成(configuration)とは、システムの実行期間中にコンポーネント、コネクタ、およびデータ間のアーキテクチャ関係の構造を指します。
プロパティは、アーキテクチャ内の制約のセットによって誘発されます。制約は、しばしばソフトウェア工学の原則 [58] をアーキテクチャ要素の側面に適用することによって動機付けられます。例えば、統一されたパイプアンドフィルタ スタイルは、コンポーネントインターフェースに一般性を適用することで、コンポーネントの再利用性とアプリケーションの設定容易性という品質を獲得します。つまり、コンポーネントを単一のインターフェースタイプに制約することです。したがって、アーキテクチャ制約は「統一されたコンポーネントインターフェース」であり、一般性の原則に基づいて、そのスタイルがアーキテクチャ内でインスタンス化されたときに、再利用可能で設定可能なコンポーネントという望ましい品質を獲得するために動機付けられます。
アーキテクチャ設計の目標は、システム要件のスーパーセットを形成する一連のアーキテクチャプロパティを持つアーキテクチャを作成することです。さまざまなアーキテクチャプロパティの相対的な重要性は、意図するシステムの性質に依存します。セクション2.3では、ネットワークベースのアプリケーションアーキテクチャにおいて特に興味深いプロパティについて検討します。
1.5 スタイル
アーキテクチャは機能的な特性と非機能的な特性の両方を体現しているため、異なる種類のシステムのアーキテクチャ、または異なる環境に設定された同じ種類のシステムのアーキテクチャを直接比較することは難しい場合があります。スタイルは、アーキテクチャを分類し、それらの共通の特性を定義するためのメカニズムです[38]。各スタイルは、コンポーネントの相互作用の抽象化を提供し、アーキテクチャの残りの部分の付随的な詳細を無視することで、相互作用パターンの本質を捉えます[117]。PerryとWolf[105]は、アーキテクチャスタイルを、様々な特定のアーキテクチャから要素タイプと形式的な側面を抽象化したものと定義し、おそらくアーキテクチャの特定の側面に焦点を当てています。アーキテクチャスタイルは、アーキテクチャ要素に関する重要な決定をカプセル化し、要素とそれらの関係に重要な制約を強調します。この定義により、アーキテクチャのコネクタのみに焦点を当てたスタイルや、コンポーネントインターフェースの特定の側面に焦点を当てたスタイルが可能です。
一方、GarlanとShaw[53]、Garlanら[56]、およびShawとClements[122]は、型付けされたコンポーネント間の相互作用パターンとしてスタイルを定義しています。具体的には、アーキテクチャスタイルは、そのスタイルのインスタンスで使用できるコンポーネントとコネクタの語彙、およびそれらを組み合わせる方法に関する一連の制約を決定します[53]。この制限されたアーキテクチャスタイルの見方は、ソフトウェアアーキテクチャの定義の直接的な結果です。つまり、アーキテクチャを実行中のシステムではなく形式的な記述として考えると、ボックスと線の図の共有パターンに基づいた抽象化が生まれます。Abowdら[1]はさらに進んで、この明示的な視点を、アーキテクチャ記述のクラスを解釈するために使用される一連の規則を定義するものとしてアーキテクチャスタイルと見なすと定義しています。
新しいアーキテクチャは、特定のスタイルのインスタンスとして定義できます[38]。アーキテクチャスタイルはソフトウェアアーキテクチャの異なる側面に対処するため、与えられたアーキテクチャは複数のスタイルで構成される場合があります。同様に、複数の基本スタイルを組み合わせて単一の調整されたスタイルを形成することもできます。
一部のアーキテクチャスタイルは、すべての形式のソフトウェアに対する「銀の弾丸」ソリューションとしてしばしば描かれます。しかし、優れた設計者は、解決すべき特定の問題のニーズに合うスタイルを選択するべきです[119]。ネットワークベースのアプリケーションに適したアーキテクチャスタイルを選択するには、問題領域[67]、したがってアプリケーションの通信ニーズを理解し、さまざまなアーキテクチャスタイルとそれらが対処する特定の懸念事項を認識し、各相互作用スタイルがネットワークベースの通信の特性に対してどのように敏感であるかを予測する能力が必要です[133]。
残念ながら、制約の調整されたセットを指すために「スタイル」という用語を使用すると、混乱を招くことがよくあります。この用法は、設計プロセスのパーソナライゼーションを強調するはずの「スタイル」の語源とは大きく異なります。Loerke[76]は、プロの建築家の仕事において個人的な様式的な懸念が何らかの役割を果たすという概念を軽蔑する章を設けています。代わりに、彼はスタイルを、過去のアーキテクチャに対する批評家の視点として説明し、利用可能な材料の選択、コミュニティの文化、または地元の支配者のエゴがアーキテクチャスタイルを決定したと述べています。言い換えれば、Loerkeは、伝統的な建物のアーキテクチャにおけるスタイルの真の源は設計に適用される一連の制約であり、特定のスタイルを達成またはコピーすることは設計者の目標の最も低いものであると見ています。制約の名前付きセットをスタイルと呼ぶことで、
一般的な制約の特性を伝えるために、私たちは建築スタイルを個別化されたデザインの指標としてではなく、抽象化の方法として使用します。
1.6 パターンとパターン言語
ソフトウェア工学におけるアーキテクチャスタイルの研究と並行して、オブジェクト指向プログラミングコミュニティでは、オブジェクトベースのソフトウェア開発において繰り返し現れる抽象化を記述するために、デザインパターンとパターン言語の活用が模索されてきました。デザインパターンは、重要かつ繰り返し現れるシステム構成要素として定義されます。パターン言語は、パターンの適用を導く構造に組織化されたパターンの体系です [70]。これらの概念は、建築家であるアレキサンダーら [3, 4] の著作に基づいています。
パターンの設計空間には、クラスの継承やインターフェースの合成など、オブジェクト指向プログラミングの技術に特有の実装上の懸念事項や、アーキテクチャスタイルで扱われるより高レベルの設計上の課題が含まれます [51]。場合によっては、アーキテクチャスタイルの記述がアーキテクチャパターンとして再構築されています [120]。しかし、パターンの主な利点は、オブジェクト間の比較的複雑な相互作用のプロトコルを単一の抽象化として記述できる点にあり [91]、行動の制約と実装の詳細の両方を含むことができます。一般的に、パターン、または複数の統合されたパターンから成るパターン言語は、オブジェクト間の望ましい相互作用のセットを実装するためのレシピと考えることができます。言い換えれば、パターンは、設計と実装の選択肢のパスをたどることによって問題を解決するプロセスを定義します [34]。
ソフトウェアアーキテクチャスタイルと同様に、ソフトウェアパターンの研究も建築における起源からやや逸脱しています。実際、アレキサンダーのパターンの概念は、建築要素の繰り返し配置ではなく、空間内で起こる繰り返しのパターン(人間の活動や感情)に焦点を当てており、イベントのパターンはそれが起こる空間から切り離せないという理解に基づいています [3]。アレキサンダーの設計哲学は、対象文化に共通する生活のパターンを特定し、そのパターンが自然に起こるように空間を差別化するために必要な建築的な制約を決定することです。このようなパターンは、複数の抽象化レベルとすべてのスケールに存在します。
世界の要素として、各パターンは、特定のコンテキスト、そのコンテキスト内で繰り返し起こる特定の力のシステム、そしてこれらの力を解決する特定の空間的配置との間の関係です。言語の要素として、パターンは、この空間的配置を、与えられた力のシステムを解決するために、どこでもコンテキストが適切である場合に、繰り返し使用する方法を示す指示です。
要するに、パターンは、世界で起こるものであり、そのものを作成する方法と、いつそれを作成しなければならないかを示すルールでもあります。それはプロセスとものであり、生きているものの記述と、そのものを生成するプロセスの記述でもあります。 [3]
多くの点で、アレキサンダーのパターンは、OOPL研究のデザインパターンよりもソフトウェアアーキテクチャスタイルに共通点があります。アーキテクチャスタイルは、調整された制約のセットとして、システムに望まれるアーキテクチャ的特性を引き出すために設計空間に適用されます。スタイルを適用することで、アーキテクターはソフトウェア設計空間を差別化し、結果がアプリケーションに内在する力によりよくマッチし、自然なパターンと衝突するのではなく、それを強化するシステムの振る舞いを導くことを目指します。
1.7 ビュー
アーキテクチャの視点は、しばしばアプリケーションに特化しており、アプリケーションの領域に基づいて大きく異なります。... 私たちは、時間的な問題、状態と制御のアプローチ、データ表現、トランザクションのライフサイクル、セキュリティ対策、ピーク需要とグレースフルデグラデーションなど、さまざまな問題に対処するアーキテクチャの視点を見てきました。間違いなく、さらに多くの可能な視点が存在します。[70]
システム内の多くのアーキテクチャや、それらのアーキテクチャを構成する多くのアーキテクチャスタイルに加えて、アーキテクチャを多くの異なる視点から見ることも可能です。PerryとWolf [105]は、ソフトウェアアーキテクチャにおける3つの重要なビューを説明しています:プロセス、データ、接続ビューです。プロセスビューは、コンポーネント間のデータフローと、データに関連するコンポーネント間の接続の一部の側面を強調します。データビューは、処理フローを強調し、コネクタにはあまり重点を置きません。接続ビューは、コンポーネント間の関係とコミュニケーションの状態を強調します。 特定のアーキテクチャのケーススタディでは、複数のアーキテクチャビューが一般的です[9]。一つのアーキテクチャ設計方法論である4+1ビューモデル[74]は、ソフトウェアアーキテクチャの記述を、特定の懸念に対処する5つの並行するビューを使用して整理します。
1.8 関連研究
ここでは、ソフトウェアアーキテクチャを定義する、またはソフトウェアアーキテクチャスタイルを記述する研究分野のみを取り上げます。ソフトウェアアーキテクチャ研究の他の分野には、アーキテクチャ分析手法、アーキテクチャの回復とリエンジニアリング、アーキテクチャ設計のためのツールと環境、仕様から実装までのアーキテクチャの精緻化、および展開されたソフトウェアアーキテクチャのケーススタディが含まれます [55]。スタイル分類、分散プロセスパラダイム、ミドルウェアに関する関連研究は第3章で議論されます。
1.8.1 設計方法論
ソフトウェアアーキテクチャに関する初期の研究のほとんどは設計方法論に集中していました。例えば、オブジェクト指向設計 [25] は、問題を構造化する方法を提唱し、自然とオブジェクトベースのアーキテクチャ(または、より正確には他の形式のアーキテクチャには自然と導かれない)に導きます。アーキテクチャレベルでの設計を強調する最初の設計方法論の一つにJackson System Development (JSD) [30] があります。JSDは、問題の分析を意図的に構造化して、パイプアンドフィルター(データフロー)とプロセス制約を組み合わせたアーキテクチャスタイルに導きます。これらの設計方法論は、通常、一つのスタイルのアーキテクチャのみを生成する傾向があります。 アーキテクチャの分析と開発のための方法論を調査する初期の研究があります。Kazmanらは、シナリオベースの分析によるSAAM [68] やATAM [69] を使ったアーキテクチャのトレードオフ分析を通じて、設計のアーキテクチャ的側面を引き出す設計手法を記述しています。Shaw [119] は、自動車のクルーズコントロールシステムのためのさまざまなボックスアンドアローデザインを比較しており、各デザインは異なる設計方法論を使用し、いくつかのアーキテクチャスタイルを包含しています。
1.8.2 設計ハンドブック、デザインパターン、パターン言語
Shaw [117] は、伝統的な工学分野と同じような形でアーキテクチャハンドブックの開発を提唱しています。オブジェクト指向プログラミングコミュニティは、デザインパターンのカタログ作成において主導権を握っており、その代表例として「Gang of Four」の書籍 [51] やCoplienとSchmidtによって編集されたエッセイ [33] が挙げられます。
ソフトウェアデザインパターンは、アーキテクチャスタイルよりも問題指向である傾向があります。Shaw [120] は、[53] で説明されたアーキテクチャスタイルに基づいて、8つのアーキテクチャパターンの例を提示しており、各アーキテクチャに最適な問題の種類に関する情報を含んでいます。Buschmannら [28] は、オブジェクトベース開発に共通するアーキテクチャパターンを包括的に検証しています。どちらの参考文献も純粋に記述的であり、アーキテクチャパターン間の違いを比較したり説明したりする試みはありません。
TepfenhartとCusick [129] は、2次元マップを使用して、ドメイン分類、ドメインモデル、アーキテクチャスタイル、フレームワーク、キット、デザインパターン、アプリケーションを区別しています。このトポロジーでは、デザインパターンはソフトウェアアーキテクチャの構成要素として使用される事前定義された設計構造であり、アーキテクチャスタイルはアプリケーションドメインに依存しないアーキテクチャファミリーを識別する操作特性のセットです。しかし、彼らはアーキテクチャ自体を定義していません。
1.8.3 参照モデルとドメイン固有ソフトウェアアーキテクチャ (DSSA)
参照モデルは、アーキテクチャを記述し、コンポーネントがどのように関連しているかを示す概念的なフレームワークを提供するために開発されます [117]。OMGによって開発されたObject Management Architecture (OMA) [96] は、ブローカードされた分散オブジェクトアーキテクチャの参照モデルとして、オブジェクトが定義・作成される方法、クライアントアプリケーションがオブジェクトを呼び出す方法、およびオブジェクトが共有・再利用される方法を指定します。焦点は、効率的なアプリケーション相互作用ではなく、分散オブジェクトの管理にあります。
Hayes-Rothら [62] は、ドメイン固有ソフトウェアアーキテクチャ (DSSA) を次のように定義しています: a) 重要なアプリケーションドメインのための一般的な計算フレームワークを記述する参照アーキテクチャ、b) コンポーネントライブラリ、その中で…
特定のアプリケーション要件を満たすために、アーキテクチャ内のコンポーネントを選択および設定するためのアプリケーション構成方法が含まれています。Tracz [130]は、DSSA(ドメイン固有ソフトウェアアーキテクチャ)の一般的な概要を提供しています。
DSSAプロジェクトは、ドメイン要件に合った特定のアーキテクチャスタイルにソフトウェア開発の空間を制限することによって、アーキテクチャの決定を実行中のシステムに移行することに成功しています [88]。例としては、航空電子工学向けのADAGE [10]、適応型知能システム向けのAIS [62]、ミサイル誘導・航法・制御システム向けのMetaH [132]などが挙げられます。DSSAは、各システムに特化したアーキテクチャスタイルを選択するのではなく、共通のアーキテクチャドメイン内でのコンポーネントの再利用を重視しています。
1.8.4 アーキテクチャ記述言語 (ADL)
最近発表されたソフトウェアアーキテクチャに関する研究の多くは、アーキテクチャ記述言語(ADL)の領域にあります。MedvidovicとTaylor [86]によると、ADLとは、ソフトウェアシステムの概念的アーキテクチャを明示的に指定およびモデル化するための機能を提供する言語であり、少なくとも以下の要素を含みます:コンポーネント、コンポーネントインターフェース、コネクタ、およびアーキテクチャ構成。
Darwinは、多様な相互作用メカニズムを使用して多様なコンポーネントで構成されるシステムの構造を指定するための汎用的な表記法を目指した宣言型言語です [81]。Darwinの興味深い特徴は、分散アーキテクチャや動的に構成されるアーキテクチャを指定できることです [82]。UniCon [118]は、限定されたセットのコンポーネントとコネクタの例からアーキテクチャを構成するための言語および関連ツールセットです。Wright [5]は、相互作用プロトコルによってコネクタタイプを指定することで、アーキテクチャコンポーネント間の相互作用を形式化する基盤を提供しています。
設計方法論と同様に、ADLは特定のアーキテクチャの前提を導入することがあり、それによって一部のアーキテクチャスタイルを記述する能力に影響を与えたり、既存のミドルウェアの前提と競合したりする可能性があります [38]。場合によっては、ADLは単一のアーキテクチャスタイルに特化して設計されており、汎用性を犠牲にすることで特殊な記述と分析の能力を向上させます。たとえば、C2SADEL [88]は、C2スタイル [128]で開発されたアーキテクチャを記述するために特化して設計されたADLです。一方、ACME [57]は、できるだけ汎用的であることを目指したADLですが、その代償として、スタイルに特化した分析や実際のアプリケーションの構築をサポートしません。その代わりに、分析ツール間の交換に焦点を当てています。
1.8.5 形式的アーキテクチャモデル
Abowdら [1]は、アーキテクチャスタイルは、アーキテクチャ記述(ボックスとライン図)の構文領域からアーキテクチャの意味論領域への小さなマッピングセットとして形式的に記述できると主張しています。ただし、これはアーキテクチャが実行中のシステムの抽象化ではなく、記述そのものであると仮定しています。
InverardiとWolf [65]は、化学抽象機械(CHAM)形式を用いて、ソフトウェアアーキテクチャ要素を化学物質としてモデル化し、その反応を明示的に規定されたルールによって制御します。これは、利用可能なデータ要素をどのように変換するかに従ってコンポーネントの動作を指定し、個々の変換を全体のシステム結果に伝播するための合成ルールを使用します。このモデルは興味深いですが、データストリームの変換を超える目的を持つアーキテクチャを記述するためにCHAMをどのように使用できるかは不明です。
Rapide [78]は、システムアーキテクチャを定義およびシミュレートするために特別に設計された並行イベントベースのシミュレーション言語です。シミュレータは、相互接続に対するアーキテクチャ制約への適合性を分析するために使用できる部分的に順序付けられたイベントのセットを生成します。Le Métayer [75]は、グラフとグラフ文法を用いたアーキテクチャ定義の形式化を提示しています。
1.9 まとめ
この章では、本論文の背景を検討しました。ソフトウェアアーキテクチャの概念に関する一貫した用語セットを導入し、形式化することは、特にデータを重要なアーキテクチャ要素として含めない従来の研究が多く存在するため、アーキテクチャとアーキテクチャ記述の間で混乱を避けるために必要です。最後に、ソフトウェアアーキテクチャおよびアーキテクチャスタイルに関連する他の研究を概観しました。
次の2つの章では、ネットワークベースのアプリケーションアーキテクチャに焦点を当て、そのアーキテクチャ設計を導くためにスタイルをどのように使用できるかを説明し、その後、ネットワークベースのハイパーメディアのアーキテクチャにスタイルを適用した場合に誘発されるアーキテクチャ的特性を強調する分類方法論を使用して、一般的なアーキテクチャスタイルを概観します。
第2章
コンソールログ
// これはコンソールにメッセージを表示するためのコマンドです
console.log("こんにちは、世界!");
変数とデータ型
// 文字列型の変数を定義
let greeting = "こんにちは";
// 数値型の変数を定義
let number = 42;
// ブール型の変数を定義
let isTrue = true;
条件分岐
// 条件によって異なる処理を実行
if (number > 50) {
console.log("数値は50よりも大きいです");
} else {
console.log("数値は50以下です");
}
ループ処理
// 0から4までの数値をコンソールに表示
for (let i = 0; i < 5; i++) {
console.log(i);
}
関数
// 2つの数値を加算する関数
function add(a, b) {
return a + b;
}
// 関数を呼び出して結果を表示
let result = add(3, 7);
console.log("結果: " + result);
ネットワークベースのアプリケーションアーキテクチャ
この章では、背景となる資料の議論を続け、ネットワークベースのアプリケーションアーキテクチャに焦点を当て、そのアーキテクチャ設計を導くためにスタイルをどのように使用できるかについて説明します。
2.1 範囲
ソフトウェアシステムには複数のレベルでアーキテクチャが存在します。本論文では、ソフトウェアアーキテクチャの最も抽象化されたレベル、すなわちコンポーネント間の相互作用がネットワーク通信で実現可能なレベルを検討します。研究対象のスタイル間の差異の次元を減らすため、ネットワークベースのアプリケーションアーキテクチャのスタイルに議論を限定します。
2.1.1 ネットワークベース vs. 分散
ネットワークベースアーキテクチャと一般的なソフトウェアアーキテクチャの主な違いは、コンポーネント間の通信がメッセージパッシングに制限されていること [6]、またはコンポーネントの配置に基づいて実行時に選択されるより効率的なメカニズムがこれに相当することです [128]。 Tanenbaum と van Renesse [127] は、分散システムとネットワークベースシステムを区別しています。分散システムとは、ユーザーにとっては通常の集中型システムのように見えるが、複数の独立したCPU上で動作するシステムです。一方、ネットワークベースシステムとは、ネットワークを介した操作が可能ではあるが、必ずしもユーザーに対して透過的ではない方式で動作するシステムです。場合によっては、ネットワークリクエストを必要とするアクションとローカルシステムで満たされるアクションの違いをユーザーに認識させることが望ましいことがあります。特に、ネットワーク利用が追加の取引コストを意味する場合です [133]。本論文は、ユーザーに対して透過性を保つスタイルに限定しないことで、ネットワークベースシステムをカバーします。
2.1.2 アプリケーションソフトウェア vs. ネットワーキングソフトウェア
本論文の範囲に対するもう一つの制限は、オペレーティングシステム、ネットワーキングソフトウェア、およびネットワークをシステムサポートのみに使用する一部のアーキテクチャスタイル(例: プロセス制御スタイル [53])を除外し、アプリケーションアーキテクチャに議論を限定することです。アプリケーションはシステムの「ビジネスを意識した」機能を表します [131]。アプリケーションソフトウェアアーキテクチャは、ユーザーアクションの目標が機能的なアーキテクチャプロパティとして表現可能な、システム全体の抽象化レベルです。例えば、ハイパーメディアアプリケーションは、情報ページの位置、リクエストの実行、およびデータストリームのレンダリングに関心を持つ必要があります。これは、ネットワーキング抽象化とは対照的です。ネットワーキング抽象化では、ビットが移動する理由に関係なく、ビットをある場所から別の場所に移動することが目的です。アプリケーションレベルでのみ、ユーザーアクションごとの相互作用の数、アプリケーション状態の位置、すべてのデータストリームの有効スループット(単一のデータストリームの潜在的スループットとは対照的に)、ユーザーアクションごとに実行される通信の範囲などを基に設計のトレードオフを評価できます。
2.2 アプリケーションアーキテクチャの設計評価
この論文の目的の一つは、与えられたアプリケーションドメインに最適なアーキテクチャを選択または作成するための設計指針を提供することです。アーキテクチャはアーキテクチャ設計の実現であり、設計そのものではないことを念頭に置いてください。アーキテクチャはその実行時特性によって評価できますが、明らかに、すべてを実装する前に候補となるアーキテクチャ設計に適用できる評価メカニズムを望むでしょう。残念ながら、アーキテクチャ設計は客観的に評価し比較することが非常に難しいことで知られています。創造的な設計の成果物の多くと同じように、アーキテクチャは通常、完成された作品として提示され、まるで設計がアーキテクトの頭から完全に形を成して出てきたかのように見えます。アーキテクチャ設計を評価するためには、システムに課される制約の背後にある設計理由を検討し、それらの制約から導き出される特性をアプリケーションの目的と比較する必要があります。
第一レベルの評価は、アプリケーションの機能要件によって設定されます。たとえば、プロセス制御アーキテクチャの設計を分散型ハイパーメディアシステムの要件に対して評価することは意味がありません。なぜなら、アーキテクチャが機能しない場合、比較は無意味だからです。これによりいくつかの候補が除外されるかもしれませんが、ほとんどの場合、アプリケーションの機能ニーズを満たすことができる多くの他のアーキテクチャ設計が残ります。残りの設計は、非機能要件に対する相対的な重点の違いによって異なります。つまり、各アーキテクチャがシステムにとって必要とされるさまざまな非機能的なアーキテクチャ特性をどの程度サポートするかです。特性はアーキテクチャ制約の適用によって生み出されるため、各アーキテクチャ内の制約を特定し、各制約によって誘導される特性セットを評価し、設計の累積特性をアプリケーションに必要な特性と比較することで、異なるアーキテクチャ設計を評価および比較することが可能です。
前章で説明したように、アーキテクチャスタイルは、参照を容易にするために名前が付けられた、調整されたアーキテクチャ制約のセットです。各アーキテクチャ設計決定は、スタイルの適用と見なすことができます。制約を追加することで新しいスタイルが導き出されるため、すべての可能なアーキテクチャスタイルの空間を、nullスタイル(空の制約セット)をルートとする派生ツリーと考えることができます。制約が衝突しない場合、スタイルは組み合わされてハイブリッドスタイルを形成し、最終的にはアーキテクチャ設計の完全な抽象化を表すハイブリッドスタイルに至ります。したがって、アーキテクチャ設計を分析するには、その制約セットを派生ツリーに分解し、そのツリーが表す制約の累積的効果を評価します。各基本スタイルによって誘導される特性を理解すれば、派生ツリーをたどることで設計全体のアーキテクチャ特性を理解することができます。その後、アプリケーションの特定のニーズを設計の特性と照合できます。比較は、どのアーキテクチャ設計がそのアプリケーションに対して最も望ましい特性を満たすかを特定するという比較的単純な問題になります。
ある制約の効果が他の制約の利点を打ち消す可能性がある場合に注意する必要があります。それにもかかわらず、経験豊富なソフトウェアアーキテクトは、与えられたアプリケーションドメインに対してアーキテクチャ制約の派生ツリーを構築し、そのドメイン内のアプリケーションに対して多くの異なるアーキテクチャ設計を評価するためにそのツリーを使用することが可能です。したがって、派生ツリーを構築することで、アーキテクチャ設計の指針を提供するメカニズムが得られます。
スタイルツリー内のアーキテクチャ特性の評価は、ニーズに固有のものです。
特定のアプリケーションドメインにおけるアーキテクチャ設計の評価は、特定の制約の影響がしばしばアプリケーションの特性に依存するため、複雑です。例えば、パイプアンドフィルタースタイルは、コンポーネント間でデータ変換を必要とするシステム内で使用される場合、いくつかの肯定的なアーキテクチャ特性を可能にしますが、制御メッセージのみで構成されるシステムではオーバーヘッドしか加えません。異なるアプリケーションドメイン間でアーキテクチャ設計を比較することはめったに有用ではないため、一貫性を確保する最も簡単な方法は、ツリーをドメイン固有にすることです。
設計評価は、しばしばトレードオフの間で選択する問題です。PerryとWolf [105]は、各プロパティに対してそのアーキテクチャに対する相対的な重要性を示す数値的な重みを付けることにより、トレードオフを明示的に認識する方法を説明しています。これにより、候補となる設計を比較するための正規化された指標を提供します。しかし、意味のある指標とするためには、各重みはすべてのプロパティにわたって一貫した客観的な尺度を用いて慎重に選択されなければなりません。実際には、そのような尺度は存在しません。アーキテクトが結果が彼らの直感に合うまで重みの値をいじるのではなく、私はすべての情報をアーキテクトに容易に視認できる形で提示し、アーキテクトの直感を視覚的なパターンによって導くことを好みます。これは次の章で示されます。
2.3 主要な関心事のアーキテクチャ的特性
このセクションでは、この論文においてアーキテクチャスタイルを区別し分類するために使用されるアーキテクチャ的特性について説明します。これは包括的なリストを意図したものではありません。調査した限定されたスタイルのセットによって明確に影響を受ける特性のみを記載しています。ソフトウェア品質とも呼ばれる追加の特性については、ソフトウェア工学のほとんどの教科書で扱われています(例: [58])。Bassら [9] は、ソフトウェアアーキテクチャに関連する品質について考察しています。
2.3.1 パフォーマンス
ネットワークベースのアプリケーションのスタイルに焦点を当てる主な理由の1つは、コンポーネント間の相互作用がユーザーが感じるパフォーマンスやネットワーク効率を決定する主要な要因となることがあるためです。アーキテクチャスタイルはこれらの相互作用の性質に影響を与えるため、適切なアーキテクチャスタイルの選択は、ネットワークベースのアプリケーションの展開における成功と失敗を分ける可能性があります。 ネットワークベースのアプリケーションのパフォーマンスは、まずアプリケーション要件によって、次に選択された相互作用スタイル、続いて実現されたアーキテクチャ、そして最後に各コンポーネントの実装によって制約されます。言い換えると、ソフトウェアはアプリケーションのニーズを満たすための基本的なコストを避けることができません。例えば、アプリケーションがデータをシステムAに保存しシステムBで処理する必要がある場合、ソフトウェアはデータをAからBに移動する必要があります。同様に、アーキテクチャは相互作用スタイルが許容する以上に効率的になることはできません。例えば、データをAからBに移動するための多数の相互作用のコストは、AからBへの単一の相互作用のコストを下回ることはできません。最後に、アーキテクチャの品質に関係なく、コンポーネントの実装がデータを生成し、受け手がデータを消費する速度よりも速く相互作用が行われることはありません。
2.3.1.1 ネットワークパフォーマンス
ネットワークパフォーマンスの測定は、通信の一部の属性を記述するために使用されます。スループット_は、アプリケーションデータと通信オーバーヘッドの両方を含む情報がコンポーネント間で転送される速度です。_オーバーヘッド_は、初期設定オーバーヘッドと相互作用ごとのオーバーヘッドに分けることができ、この区別は、複数の相互作用間で設定オーバーヘッドを共有できるコネクタ(_償却)を特定するのに役立ちます。_帯域幅_は、特定のネットワークリンク上の最大利用可能なスループットの尺度です。_使用可能な帯域幅_は、アプリケーションが実際に利用できる帯域幅の部分を指します。 スタイルは、ユーザーアクションごとの相互作用の数とデータ要素の粒度に影響を与えることでネットワークパフォーマンスに影響を与えます。小さな、厳密に型付けされた相互作用を促進するスタイルは、既知のコンポーネント間で小さなデータ転送を行うアプリケーションでは効率的ですが、大きなデータ転送やネゴシエーションインターフェースを伴うアプリケーションでは過剰なオーバーヘッドを引き起こします。同様に、大きなデータストリームをフィルタリングするために配置された複数のコンポーネントの調整を含むスタイルは、主に小さな制御メッセージを必要とするアプリケーションには不向きです。
2.3.1.2 ユーザーが感じるパフォーマンス
ユーザーが感じるパフォーマンスは、ネットワークパフォーマンスとは異なり、アクションのパフォーマンスは、ネットワークが情報を移動する速度ではなく、アプリケーションの前にいるユーザーへの影響として測定されます。ユーザーが感じるパフォーマンスの主な尺度は、レイテンシと完了時間です。 _レイテンシ_は、初期刺激から最初の応答の兆候までの時間です。レイテンシは、ネットワークベースのアプリケーションアクションの処理中にいくつかの時点で発生します:1) アプリケーションがアクションを開始するイベントを認識するのにかかる時間、2) コンポーネント間の相互作用を設定するのにかかる時間、3) 各相互作用をコンポーネントに送信するのにかかる時間、4) それらのコンポーネントで各相互作用を処理するのにかかる時間、そして、 5) 完了するのにかかる
アプリケーションが使用可能な結果のレンダリングを開始する前に、インタラクションの結果を十分に転送および処理する必要があります。重要な点として、(3)と(5)のみが実際のネットワーク通信を表しますが、これら5つのポイントすべてがアーキテクチャスタイルの影響を受ける可能性があります。さらに、ユーザーアクションごとの複数のコンポーネントインタラクションは、並列で行われない限り、レイテンシに加算されます。
_完了時間_は、アプリケーションのアクションを完了するのにかかる時間です。完了時間は、前述のすべての測定値に依存します。アクションの完了時間とレイテンシの差は、アプリケーションが受信したデータをどの程度段階的に処理しているかを示します。たとえば、大きな画像を受信しながらレンダリングできるWebブラウザは、画像全体が完全に受信されるまでレンダリングを待つブラウザよりも、ユーザーが感じるパフォーマンスが大幅に向上します。両者が同じネットワークパフォーマンスを経験している場合でもです。
レイテンシを最適化するための設計上の考慮事項は、しばしば完了時間を悪化させる副作用を持つことに注意することが重要であり、その逆もまた同様です。たとえば、データストリームの圧縮は、アルゴリズムがエンコードされた変換を生成する前にデータの大部分をサンプリングする場合、より効率的なエンコーディングを生成し、エンコードされたデータをネットワーク経由で転送するための完了時間を短縮することができます。しかし、この圧縮がユーザーアクションに応じてオンザフライで実行される場合、転送前に大きなサンプルをバッファリングすると、許容できないレイテンシが発生する可能性があります。これらのトレードオフをバランスさせることは困難であり、特に受信側がレイテンシ(例:Webブラウザ)と完了時間(例:Webクローラー)のどちらをより重視するかが不明な場合に顕著です。
2.3.1.3 ネットワーク効率
ネットワークベースのアプリケーションに関する興味深い観察は、最良のアプリケーションパフォーマンスはネットワークを使用しないことで得られるということです。これは本質的に、ネットワークベースのアプリケーションにとって最も効率的なアーキテクチャスタイルは、可能な限りネットワークの使用を効果的に最小化できるものであることを意味します。これには、以前のインタラクションの再利用(キャッシング)、ユーザーアクションに関連するネットワークインタラクションの頻度の削減(複製データと切断操作)、またはデータの処理をデータのソースに近づけることによる一部のインタラクションの必要性の除去(モバイルコード)が含まれます。
さまざまなパフォーマンス問題の影響は、多くの場合、アプリケーションの配布範囲に関連しています。ローカル条件でのスタイルの利点は、グローバル条件に直面すると欠点になる可能性があります。したがって、スタイルの特性は、インタラクションの距離に関連してフレーム化する必要があります:単一プロセス内、単一ホスト上のプロセス間、ローカルエリアネットワーク(LAN)内、またはワイドエリアネットワーク(WAN)全体に広がる場合です。単一の組織が関与するWANを越えたインタラクションと、複数の信頼境界が関与するインターネットを越えたインタラクションを比較すると、追加の懸念が明らかになります。
2.3.2 スケーラビリティ
スケーラビリティとは、アーキテクチャが多数のコンポーネント、またはアクティブな構成内のコンポーネント間のインタラクションをサポートする能力を指します。スケーラビリティは、コンポーネントを簡素化すること、サービスを多数のコンポーネントに分散すること(インタラクションの分散化)、および監視の結果としてインタラクションと構成を制御することで向上させることができます。スタイルは、アプリケーション状態の位置、配布の範囲、およびコンポーネント間の結合を決定することによってこれらの要因に影響を与えます。
スケーラビリティは、インタラクションの頻度、コンポーネントの負荷が時間的に均等に分散されているかピークで発生するか、インタラクションが保証された配信を必要とするかベストエフォートであるか、リクエストが同期処理か非同期処理を必要とするか、環境が制御されているか無秩序であるか(つまり、他のコンポーネントを信頼できるか)によっても影響を受けます。
2.3.3 シンプルさ
アーキテクチャスタイルがシンプルさを誘発する主要な手段は、コンポーネント内の機能割り当てに対して関心の分離の原則を適用することです。もし機能が個々のコンポーネントの複雑さを大幅に減らすように割り当てられるなら、それらは理解しやすく、実装しやすくなります。同様に、そのような分離は、アーキテクチャ全体について推論するタスクを容易にします。ネットワークベースのシステムでは、複雑さ、理解しやすさ、検証可能性の品質がシンプルさという一般的な特性の下にまとめられることを選択しました。なぜなら、それらは密接に関連しているからです。
アーキテクチャ要素に一般性の原則を適用することもシンプルさを向上させます。なぜなら、アーキテクチャ内の変動を減らすからです。コネクタの一般性はミドルウェアにつながります[22]。
2.3.4 変更容易性
変更容易性は、アプリケーションアーキテクチャに対して変更を加える容易さについてです。変更容易性は、以下で説明するように、進化可能性、拡張性、カスタマイズ性、設定可能性、再利用可能性にさらに分解できます。ネットワークベースシステムの特定の懸念事項は、システム全体を停止および再起動することなく、デプロイされたアプリケーションに対して変更を加える動的変更容易性[98]です。
ユーザーの要件に完全に一致するソフトウェアシステムを構築することが可能であったとしても、社会が変化するのと同様に、それらの要件は時間とともに変化します。ネットワークベースアプリケーションに参加するコンポーネントが複数の組織境界にまたがって分散している可能性があるため、システムは、新しい実装がその拡張機能を利用することを妨げることなく、古い実装と新しい実装が共存する漸進的で断片的な変更に備える必要があります。
2.3.4.1 進化可能性
進化可能性は、コンポーネントの実装を他のコンポーネントに悪影響を与えずに変更できる程度を表します。コンポーネントの静的な進化は、通常、実装によってアーキテクチャの抽象化がどれだけうまく強制されるかに依存し、特定のアーキテクチャスタイルに特有のものではありません。しかし、動的な進化は、アプリケーション状態の維持と場所に関する制約を含むスタイルによって影響を受ける可能性があります。分散システムにおける部分的な障害状態から回復するために使用される技術[133]は、動的な進化をサポートするために使用されることがあります。
2.3.4.2 拡張性
拡張性は、システムに機能を追加する能力として定義されます[108]。動的な拡張性は、デプロイされたシステムに機能を追加することができ、システムの他の部分に影響を与えないことを意味します。拡張性は、イベントベースの統合によって例示されるように、コンポーネント間の結合を減らすことによってアーキテクチャスタイル内で誘発されます。
2.3.4.3 カスタマイズ性
カスタマイズ性とは、アーキテクチャ要素の動作を一時的に特殊化して、通常とは異なるサービスを実行できる能力を指します。コンポーネントは、そのコンポーネントのサービスの1つのクライアントによって拡張され、そのコンポーネントの他のクライアントに悪影響を与えない場合、カスタマイズ可能です[50]。カスタマイズをサポートするスタイルは、シンプルさとスケーラビリティも向上させる可能性があります。なぜなら、サービスコンポーネントはサイズと複雑さを減らし、最も頻繁に使用されるサービスを直接実装し、あまり使用されないサービスをクライアントによって定義できるようにするためです。カスタマイズ性は、リモート評価とコードオンデマンドスタイルによって誘発される特性です。
2.3.4.4 設定可能性
設定可能性は、拡張性と再利用可能性の両方に関連しています。なぜなら、デプロイ後のコンポーネント、またはコンポーネントの設定を変更して、新しいサービスやデータ要素タイプを使用できるようにすることを指すからです。パイプアンドフィルタとコードオンデマンドスタイルは、それぞれ設定とコンポーネントの設定可能性を誘発する2つの例です。
2.3.4.5 再利用可能性
再利用可能性は、そのコンポーネント、コネクタ、またはデータ要素が複数のアプリケーションで使用できる場合のアプリケーションアーキテクチャの特性です。
データ要素は、変更を加えることなく他のアプリケーションで再利用できます。アーキテクチャスタイル内で再利用性を誘発する主要なメカニズムは、コンポーネント間の結合度(識別情報の知識)を減らし、コンポーネントインターフェースの汎用性を制約することです。均一なパイプアンドフィルタースタイルは、これらの制約の例です。
2.3.5 可視性
スタイルは、ネットワークベースのアプリケーション内での相互作用の可視性にも影響を与えることができます。これは、インターフェースを汎用性で制限したり、監視へのアクセスを提供したりすることで実現されます。ここでの可視性とは、あるコンポーネントが他の2つのコンポーネント間の相互作用を監視または仲介する能力を指します。可視性は、相互作用の共有キャッシュによるパフォーマンスの向上、階層化されたサービスによるスケーラビリティ、反射的監視による信頼性、仲介者(例:ネットワークファイアウォール)による相互作用の検査を可能にすることでセキュリティを向上させることができます。モバイルエージェントスタイルは、可視性の欠如がセキュリティ上の懸念を引き起こす例です。 この「可視性」という用語の使用法は、Ghezziら[58]の使用法とは異なります。彼らは製品ではなく開発プロセスへの可視性を指しています。
2.3.6 移植性
ソフトウェアが異なる環境で実行できる場合、そのソフトウェアは移植性があると言えます[58]。移植性を誘発するスタイルには、処理されるデータとともにコードを移動する仮想マシンやモバイルエージェントスタイル、およびデータ要素を標準化された形式のセットに制約するスタイルが含まれます。
2.3.7 信頼性
アプリケーションアーキテクチャの観点から見た信頼性は、コンポーネント、コネクタ、またはデータ内での部分的な障害が発生した場合に、システムレベルで障害が発生しやすい程度と見なすことができます。スタイルは、単一障害点を回避し、冗長性を可能にし、監視を可能にし、障害の範囲を回復可能なアクションに限定することで、信頼性を向上させることができます。
2.4 まとめ
本章では、ネットワークベースのアプリケーションアーキテクチャに焦点を当て、それらのアーキテクチャ設計をガイドするためにスタイルをどのように使用できるかを説明することで、本論文の範囲を検討しました。また、今後の論文でアーキテクチャスタイルを比較・評価するために使用する一連のアーキテクチャ特性を定義しました。
次の章では、ネットワークベースのアプリケーションソフトウェアの一般的なアーキテクチャスタイルを分類フレームワークに基づいて調査し、それぞれのスタイルを、プロトタイプ的なネットワークベースハイパーメディアシステムのアーキテクチャに適用した場合に誘発されるアーキテクチャ特性に従って評価します。
第3章
ネットワークベースのアーキテクチャスタイル
この章では、ネットワークベースのアプリケーションソフトウェアの一般的なアーキテクチャスタイルについて、分類フレームワークに基づいて調査します。このフレームワークは、各スタイルを、プロトタイプ的なネットワークベースのハイパーメディアシステムのアーキテクチャに適用した場合に生じるアーキテクチャ的特性に従って評価します。
3.1 分類方法論
ソフトウェアを構築する目的は、特定の相互作用のトポロジーを作成したり、特定のコンポーネントタイプを使用したりすることではありません。それは、アプリケーションのニーズを満たすか、それを超えるシステムを作成することです。システムの設計に選ばれるアーキテクチャスタイルは、それらのニーズに適合しなければなりません。その逆ではありません。したがって、有用な設計ガイダンスを提供するために、アーキテクチャスタイルの分類は、それらのスタイルによって引き起こされるアーキテクチャ特性に基づくべきです。
3.1.1 分類のためのアーキテクチャスタイルの選択
分類に含まれるアーキテクチャスタイルのセットは、すべての可能なネットワークベースのアプリケーションスタイルを網羅しているわけではありません。実際、新しいスタイルは、調査されたスタイルのいずれかにアーキテクチャ制約を追加するだけで形成できます。私の目標は、特にソフトウェアアーキテクチャの文献ですでに特定されているスタイルの代表的なサンプルを説明し、他のスタイルが開発されたときに分類に追加できるフレームワークを提供することです。
私は意図的に、調査されたスタイルのいずれかと組み合わせてネットワークベースのアプリケーションを形成する際に、通信や相互作用の特性を強化しないスタイルを除外しました。たとえば、ブラックボードアーキテクチャスタイル[95]は、中央リポジトリと、リポジトリに対して機会的に操作する一連のコンポーネント(知識源)で構成されています。ブラックボードアーキテクチャは、コンポーネントを分散させることでネットワークベースのシステムに拡張できますが、そのような拡張の特性は、分散をサポートするために選ばれた相互作用スタイル(イベントベースの統合による通知、クライアントサーバー形式のポーリング、またはリポジトリの複製)に完全に基づいています。したがって、ハイブリッドスタイルがネットワーク対応であっても、分類に含めることによる付加価値はありません。
3.1.2 スタイルによって引き起こされるアーキテクチャ特性
私の分類では、分散ハイパーメディアのシステムに適用された場合の各アーキテクチャスタイルの効果を説明する手段として、各スタイルによって引き起こされるアーキテクチャ特性の相対的な変化を使用しています。特定の特性に対するスタイルの評価は、研究されているシステム相互作用のタイプに依存することに注意してください(セクション2.2で説明)。アーキテクチャ特性は、アーキテクチャ制約を追加することで特定の特性が改善または低下する、または同時に特性の一側面を改善し、他の側面を低下させるという意味で相対的です。同様に、一つの特性を改善すると、別の特性が低下する可能性があります。
アーキテクチャスタイルの議論には、幅広いネットワークベースのシステムに適用可能なものが含まれますが、各スタイルの評価は、単一のタイプのソフトウェア(ネットワークベースのハイパーメディアシステム)のアーキテクチャへの影響に基づいて行われます。
特定のタイプのソフトウェアに焦点を当てることで、システムの設計者がそれらの利点を評価するのと同じ方法で、一つのスタイルが他のスタイルよりも優れている点を特定できます。すべてのタイプのソフトウェアに対して普遍的に望ましいとされる単一のスタイルを宣言する意図はないため、評価の焦点を制限することで、評価が必要な次元を単純に減らします。他のタイプのアプリケーションソフトウェアに対して同じスタイルを評価することは、今後の研究のための開かれた領域です。
3.1.3 可視化
この分類の主要な可視化として、スタイル対アーキテクチャ特性の表を使用します。表の値は、特定の行のスタイルが列の特性に及ぼす相対的な影響を示します。マイナス(−)記号は負の影響を、プラス(+)記号は正の影響を累積し、プラスマイナス(±)は問題領域の一部に依存することを示します。これは各セクションで提示される詳細の大まかな簡略化ですが、スタイルがアーキテクチャ特性に対処(または無視)した程度を示しています。
別の視覚化方法として、建築スタイルを分類するためのプロパティベースの派生グラフが考えられます。スタイルは、他のスタイルからどのように派生するかによって分類され、スタイル間のアークは、獲得または失われる建築プロパティによって示されます。グラフの開始点は、ヌルスタイル(制約なし)です。このようなグラフは、説明から直接導出することが可能です。
3.2 データフロースタイル
3.2.1 パイプアンドフィルタ (PF)
パイプアンドフィルタスタイルでは、各コンポーネント(フィルタ)は入力からデータのストリームを読み取り、出力にデータのストリームを生成します。通常、入力ストリームに変換を適用し、入力を完全に消費する前に出力を開始するように、増分的に処理します [53]。このスタイルは、一方向のデータフローネットワークとも呼ばれます [6]。制約は、フィルタが他のフィルタから完全に独立している必要があること(ゼロ結合)です。つまり、上流および下流のインターフェースにおいて、状態、制御スレッド、または識別子を共有してはなりません [53]。 Abowdら [1] は、Z言語を使用してパイプアンドフィルタスタイルの詳細な形式的記述を提供しています。画像処理のためのKhorosソフトウェア開発環境 [112] は、パイプアンドフィルタスタイルを使用してさまざまなアプリケーションを構築する良い例を提供しています。 GarlanとShaw [53] は、パイプアンドフィルタスタイルの利点を次のように説明しています。第一に、PFは設計者が個々のフィルタの動作を単純に組み合わせることで、システム全体の入出力を理解することを可能にします(単純性)。第二に、PFは再利用をサポートします。任意の2つのフィルタは、それらの間で伝送されるデータに同意している限り、接続できます(再利用性)。第三に、PFシステムは簡単に保守および拡張できます。既存のシステムに新しいフィルタを追加でき
表 3-1: ネットワークベースのハイパーメディアにおけるデータフロースタイルの評価
| スタイル | 派生元 | ネットワーク性能 | ユーザー知覚性能 | 効率性 | スケーラビリティ | シンプルさ | 進化性 | 拡張性 | カスタマイズ性 | 構成可能性 | 再利用性 | 可視性 | 移植性 | 信頼性 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PF | ± | + | + | + | + | + | ||||||||
| UPF | PF | - | ± | ++ | + | + | ++ | ++ | + |
(拡張性)、古いフィルタを改善されたものに置き換えることができます(進化性)。第四に、スループットやデッドロック分析などの特定の種類の専門的な分析(検証可能性)を可能にします。最後に、並行実行(ユーザが認識するパフォーマンス)を自然にサポートします。 PFスタイルの欠点には、長いパイプラインによる伝播遅延が追加されること、フィルタが入力を増分的に処理できない場合にバッチ順次処理が発生すること、およびインタラクティブ性が許されないことが含まれます。フィルタは、特定の出力ストリームが特定の入力ストリームとコントローラを共有していることを知ることができないため、環境と相互作用できません。これらの特性は、取り組む問題がデータフローストリームのパターンに適合しない場合、ユーザが認識するパフォーマンスを低下させます。 PFスタイルのあまり言及されない側面の1つは、全体のアプリケーションを確立するためにフィルタの構成を調整する「見えない手」が暗示されていることです。フィルタのネットワークは、通常、各アクティベーションの直前に配置され、アプリケーションが現在のタスクとデータストリームの性質に基づいてフィルタコンポーネントの構成を指定できるようにします(設定性)。このコントローラ機能は、システムの別の運転段階、ひいては別のアーキテクチャと見なされますが、一方が他方なしで存在することはできません。
3.2.2 統一パイプアンドフィルタ (UPF)
統一パイプアンドフィルタスタイルは、すべてのフィルタが同じインターフェースを持つ必要があるという制約を追加します。このスタイルの主な例は、UNIXオペレーティングシステムに見られます。ここでは、フィルタプロセスが1つの入力データストリーム(stdin)と2つの出力データストリーム(stdoutおよびstderr)からなるインターフェースを持っています。インターフェースを制限することで、独立して開発されたフィルタを自由に配置して新しいアプリケーションを形成できます。また、特定のフィルタの動作を理解するタスクを簡素化します。 統一インターフェースの欠点は、データをその自然な形式から変換する必要がある場合、ネットワークパフォーマンスが低下する可能性があることです。
3.3 レプリケーションスタイル
表 3-2: ネットワークベースのハイパーメディアにおけるレプリケーションスタイルの評価
| スタイル | 派生元 | ネットワーク性能 | ユーザー知覚性能 | 効率性 | スケーラビリティ | シンプルさ | 進化性 | 拡張性 | カスタマイズ性 | 構成可能性 | 再利用性 | 可視性 | 移植性 | 信頼性 | |———-|——–|——————|——————|——–|——————|————|——–|——–|—————-|————|———-|——–|——–|——–| | RR | | | ++ | | + | | | | | | | | | + | | $ | RR | | + | + | + | + | | | | | | | | |
3.3.1 レプリケートされたリポジトリ (RR)
レプリケートされたリポジトリスタイル [6] に基づくシステムは、複数のプロセスが同じサービスを提供することで、データのアクセシビリティとサービスのスケーラビリティを向上させます。これらの分散サーバーは相互作用し、クライアントに対して単一の集中型サービスであるかのような錯覚を提供します。分散ファイルシステム(例: XMS [49])やリモートバージョン管理システム(例: CVS [www.cyclic.com])が主な例です。
ユーザーが感じるパフォーマンスの向上が主な利点であり、通常のリクエストの遅延を減らすことや、プライマリサーバーの障害や意図的なネットワーク外での操作を可能にすることが挙げられます。シンプルさは中立で、レプリケーションの複雑さは、ネットワークを意識しないコンポーネントがローカルにレプリケートされたデータを透過的に操作できることによる節約によって相殺されます。一貫性の維持が主な懸念事項です。
3.3.2 キャッシュ ($)
レプリケートされたリポジトリのバリエーションとして、キャッシュスタイルがあります。これは、個々のリクエストの結果をレプリケートし、後続のリクエストで再利用できるようにするものです。この形式のレプリケーションは、潜在的なデータセットが単一のクライアントの容量をはるかに超える場合(例: WWW [20])や、リポジトリへの完全なアクセスが不要な場合に最もよく見られます。
遅延レプリケーションは、まだキャッシュされていないリクエストに対する応答時にデータがレプリケートされる場合に発生し、参照の局所性と共通の関心に依存して有用なアイテムをキャッシュに伝播させ、後で再利用できるようにします。アクティブレプリケーションは、予想されるリクエストに基づいてキャッシュ可能なエントリを事前に取得することで実行できます。
キャッシュは、ユーザーが感じるパフォーマンスの向上という点ではレプリケートされたリポジトリスタイルよりもやや劣ります。なぜなら、より多くのリクエストがキャッシュにヒットせず、最近アクセスされたデータのみがオフライン操作で利用可能になるためです。一方、キャッシュは実装がはるかに簡単で、処理とストレージをそれほど必要とせず、データがリクエストされたときにのみ送信されるため、より効率的です。キャッシュスタイルは、クライアントステートレスサーバースタイルと組み合わせるとネットワークベースになります。
3.4 階層型スタイル
表 3-3: ネットワークベースのハイパーメディアにおける階層的スタイルの評価
| スタイル | 派生元 | ネットワーク性能 | ユーザー知覚性能 | 効率性 | スケーラビリティ | シンプルさ | 進化性 | 拡張性 | カスタマイズ性 | 構成可能性 | 再利用性 | 可視性 | 移植性 | 信頼性 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CS | + | + | + | |||||||||||
| LS | - | + | + | + | + | |||||||||
| LCS | CS+LS | - | ++ | + | ++ | + | + | |||||||
| CSS | CS | - | ++ | + | + | + | + | |||||||
| C$SS | CSS+$ | - | + | + | ++ | + | + | + | + | |||||
| LC$SS | LCS+C$SS | - | ± | + | +++ | ++ | ++ | + | + | + | + | |||
| RS | CS | + | - | + | + | - | ||||||||
| RDA | CS | + | - | - | + | - |
3.4.1 クライアントサーバー (CS)
クライアントサーバー(CS)スタイルは、ネットワークベースのアプリケーションにおける最も頻繁に遭遇するアーキテクチャスタイルです。サービスを提供するサーバーコンポーネントは、それらのサービスへのリクエストを待ち受けます。サービスを実行したいクライアントコンポーネントは、コネクタを介してサーバーにリクエストを送信します。サーバーはリクエストを拒否するか実行し、クライアントにレスポンスを返します。Sinha [123] や Umar [131] により、さまざまなクライアントサーバーシステムが調査されています。 Andrews [6] は、クライアントサーバーコンポーネントを次のように説明しています:クライアントはトリガープロセスであり、サーバーはリアクティブプロセスです。クライアントはリクエストを行い、サーバーからの反応を引き起こします。したがって、クライアントは自らが選択したタイミングでアクティビティを開始し、多くの場合、リクエストが処理されるまで待機します。一方、サーバーはリクエストが行われるのを待ち、それに反応します。サーバーは通常、終了しないプロセスであり、しばしば複数のクライアントにサービスを提供します。
クライアントサーバーの制約の背後にあるのは懸念の分離の原則です。適切な機能の分離により、サーバーコンポーネントを簡素化し、拡張性を向上させるべきです。この簡素化は、通常、ユーザーインターフェースの機能をすべてクライアントコンポーネントに移す形で行われます。この分離により、インターフェースが変わらない限り、2種類のコンポーネントが独立して進化できるようになります。 クライアントサーバーの基本形は、アプリケーションの状態がクライアントとサーバーコンポーネント間でどのように分割されるかを制約しません。リモートプロシージャコール [23] やメッセージ指向ミドルウェア [131] などのコネクタ実装のメカニズムによってしばしば言及されます。
3.4.2 階層化システム (LS) および階層化クライアントサーバー (LCS)
階層化システムは階層的に組織化され、各層は上位層にサービスを提供し、下位層のサービスを使用します [53]。階層化システムは「純粋な」スタイルと見なされますが、ネットワークベースのシステムでの使用は、クライアントサーバースタイルと組み合わせて階層化クライアントサーバーを提供する場合に限られています。 階層化システムは、内側の層を隣接する外側の層以外から隠すことで、複数の層間の結合を減らし、進化性と再利用性を向上させます。例には、TCP/IP や OSI プロトコルスタック [138] などの階層化通信プロトコルの処理や、ハードウェアインターフェースライブラリが含まれます。階層化システムの主な欠点は、データの処理にオーバーヘッドとレイテンシを追加し、ユーザーが感じる性能を低下させることです [32]。 階層化クライアントサーバー(LCS)は、クライアントサーバースタイルにプロキシおよびゲートウェイコンポーネントを追加します。プロキシ [116] は、1つ以上のクライアントコンポーネントの共有サーバーとして機能し、リクエストを受け取り、必要に応じて変換してサーバーコンポーネントに転送します。ゲートウェイコンポーネントは、そのサービスをリクエストするクライアントやプロキシにとっては通常のサーバーのように見えますが、実際にはリクエストを「内側の層」サーバーに転送し、必要に応じて変換します。これらの追加の仲介コンポーネントは、負荷分散やセキュリティチェックのような機能をシステムに追加するために、複数の層で追加することができます。 情報システムの文献では、階層化クライアントサーバーに基づくアーキテクチャは、2層、3層、または多層アーキテクチャと呼ばれます [131]。 LCS は、大規模分散システムにおけるアイデンティティ管理の解決策でもあります。すべてのサーバーについて完全に知ることは、非現実的にコストがかかるためです。代わりに、サーバーは
レイヤーごとに整理されており、めったに使用されないサービスは各クライアントが直接扱うのではなく、仲介者が扱うようになっています [6]。
3.4.3 クライアントステートレスサーバー (CSS)
クライアントステートレスサーバー(CSS)スタイルは、クライアントサーバーから派生し、サーバーコンポーネントにセッション状態が保持されないという追加の制約があります。クライアントからサーバーへの各リクエストには、リクエストを理解するために必要なすべての情報が含まれている必要があり、サーバーに保存されたコンテキストを利用することはできません。セッション状態は完全にクライアント側に保持されます。
これらの制約により、可視性、信頼性、スケーラビリティが向上します。
可視性が向上する理由は、監視システムがリクエストの完全な性質を把握するために単一のリクエストデータ以上の情報を探す必要がないためです。信頼性が向上する理由は、部分的な障害からの回復が容易になるためです [133]。スケーラビリティが向上する理由は、リクエスト間で状態を保存する必要がないため、サーバーコンポーネントが迅速にリソースを解放でき、実装がさらに簡素化されるためです。
クライアントステートレスサーバーの欠点は、共有コンテキストとしてサーバーにデータを残すことができないため、一連のリクエストで送信される繰り返しデータ(インタラクションごとのオーバーヘッド)が増加し、ネットワークパフォーマンスが低下する可能性があることです。
3.4.4 クライアントキャッシュステートレスサーバー (C$SS)
クライアントキャッシュステートレスサーバー(C$SS)スタイルは、クライアントステートレスサーバーとキャッシュスタイルから派生し、キャッシュコンポーネントを追加したものです。キャッシュはクライアントとサーバーの間の仲介者として機能し、以前のリクエストに対する応答がキャッシュ可能とみなされる場合、同等の後続のリクエストに対して再利用できます。リクエストがサーバーに転送された場合にキャッシュ内の応答と同一の結果が得られる可能性がある場合に再利用されます。このスタイルを効果的に使用するシステムの例として、Sun MicrosystemsのNFSがあります [115]。
キャッシュコンポーネントを追加する利点は、一部またはすべてのインタラクションを排除する可能性があり、効率性とユーザーが感じるパフォーマンスが向上することです。
3.4.5 レイヤードクライアントキャッシュステートレスサーバー (LC$SS)
レイヤードクライアントキャッシュステートレスサーバー(LC$SS)スタイルは、レイヤードクライアントサーバーとクライアントキャッシュステートレスサーバーから派生し、プロキシやゲートウェイコンポーネントを追加したものです。LC$SSスタイルを使用するシステムの例として、インターネットのドメインネームシステム(DNS)があります。
LC$SSの利点と欠点は、単にLCSとC$SSの利点と欠点の組み合わせです。ただし、同じ先祖由来の利点は加算されないため、CSスタイルの貢献を二重にカウントしないことに注意してください。
3.4.6 リモートセッション (RS)
リモートセッション(RS)スタイルは、クライアントサーバーのバリアントであり、サーバーコンポーネントではなくクライアントコンポーネントの複雑さを最小化、または再利用を最大化しようとするものです。各クライアントはサーバー上でセッションを開始し、サーバー上で一連のサービスを呼び出し、最後にセッションを終了します。アプリケーション状態は完全にサーバーに保持されます。このスタイルは、汎用クライアント(例:TELNET [106])を使用してリモートサービスにアクセスする場合や、汎用クライアントを模倣したインターフェイス(例:FTP [107])を使用する場合に一般的に使用されます。
リモートセッションスタイルの利点は、インターフェイスをサーバー側で集中管理しやすく、機能が拡張された際に展開されているクライアント間の不整合に対する懸念が軽減されること、およびサーバーのセッションコンテキストを利用する場合に効率性が向上することです。欠点は、保存されたアプリケーション状態のためにサーバーのスケーラビリティが低下すること、および監視者がサーバーの完全な状態を知る必要があるため、インタラクションの可視性が低下することです。
3.4.7 リモートデータアクセス (RDA)
リモートデータアクセス(RDA)スタイル [131] は、クライアントサーバーのバリアントであり、アプリケーション状態をクライアントとサーバーの両方に分散させます。クライアントは、SQLなどの標準形式でデータベースクエリをリモートサーバーに送信します。サーバーはワークスペースを割り当ててクエリを実行します。
非常に大きなデータセットが生成される可能性があります。クライアントは、結果セットに対してさらに操作(テーブル結合など)を行ったり、結果を一つずつ取得したりできます。クライアントは、構造依存のクエリを構築するために、サービスのデータ構造について知っている必要があります。
リモートデータアクセスの利点は、大きなデータセットをネットワーク経由で転送することなく、サーバー側で反復的に削減できるため、効率が向上し、標準クエリ言語を使用することで可視性が向上することです。欠点は、クライアントがサーバー実装と同じデータベース操作の概念を理解する必要があるため(シンプルさに欠ける)、サーバー上にアプリケーションコンテキストを保存するとスケーラビリティが低下することです。また、部分的な障害が発生するとワークスペースが未知の状態になるため、信頼性も低下します。信頼性の問題を解決するためにトランザクションメカニズム(例:2相コミット)を使用できますが、追加の複雑さと相互作用のオーバーヘッドが発生します。
3.5 モバイルコードスタイル
モバイルコードスタイルは、処理とデータのソースまたは結果の宛先との間の距離を動的に変更するためにモビリティを利用します。これらのスタイルは、Fuggettaら[50]で包括的に検討されています。アーキテクチャレベルでは、アクティブな構成の一部としてサイト抽象化が導入され、異なるコンポーネントの場所を考慮に入れます。場所の概念を導入することで、設計レベルでコンポーネント間の相互作用のコストをモデル化することが可能になります。特に、同じ場所を共有するコンポーネント間の相互作用は、ネットワークを介した通信を含む相互作用と比較して無視できるコストであると見なされます。コンポーネントがその場所を変更することで、相互作用の近接性と品質が向上し、相互作用コストが削減され、効率とユーザーが感じるパフォーマンスが向上します。
表 3-4: ネットワークベースのハイパーメディアにおけるモバイルコードスタイルの評価
| スタイル | 派生元 | ネットワーク性能 | ユーザー知覚性能 | 効率性 | スケーラビリティ | シンプルさ | 進化性 | 拡張性 | カスタマイズ性 | 構成可能性 | 再利用性 | 可視性 | 移植性 | 信頼性 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VM | ± | + | - | + | ||||||||||
| REV | CS+VM | + | - | ± | + | + | - | + | - | |||||
| COD | CS+VM | + | + | + | ± | + | + | - | ||||||
| LCODC$SS | LC$SS+COD | - | ++ | ++ | +4+ | +±+ | ++ | + | + | + | ± | + | + | |
| MA | REV+COD | + | ++ | ± | ++ | + | + | - | + |
すべてのモバイルコードスタイルにおいて、データ要素は動的にコンポーネントに変換されます。Fuggettaら[50]は、コードのサイズをデータ要素として通常のデータ転送の節約と比較することで、特定のアクションに対してモビリティが望ましいかどうかを判断する分析を使用しています。ソフトウェアアーキテクチャの定義がデータ要素を除外している場合、これをアーキテクチャの観点からモデル化することは不可能でしょう。
3.5.1 仮想マシン (VM)
すべてのモバイルコードスタイルの基礎には、仮想マシンまたはインタープリターのスタイル[53]の概念があります。コードは何らかの方法で実行されなければならず、セキュリティと信頼性の懸念を満たすために制御された環境内で実行されることが望ましいです。これはまさに仮想マシンスタイルが提供するものです。それ自体はネットワークベースのスタイルではありませんが、クライアント-サーバースタイルのコンポーネント(REVおよびCODスタイル)と組み合わせると、一般的にそのように使用されます。 仮想マシンは、Perl[134]のような汎用言語やPostScript[2]のようなタスク固有の言語を含むスクリプト言語のエンジンとして一般的に使用されます。主な利点は、特定のプラットフォームでの命令と実装の分離(移植性)と拡張の容易さです。可視性は低下します。なぜなら、コードを見るだけで実行可能ファイルが何をするかを知るのは難しいからです。簡潔さは、
スタイルの導出 ネットパフォーマンス UP パフォーマンス 効率 スケーラビリティ 簡潔さ 進化性 拡張性 カスタマイズ 設定 再利用性 可視性 移植性 信頼性
VM ±+ -+
REV CS+VM + -± + + - + -
COD CS+VM + + + ± + + -
LCODC$SS LC$SS+COD - + + + +4 + + ± + + + + + ± + +
MA REV+COD + + + ± + + + + - +
表3-4. ネットワークベースのハイパーメディアのためのモバイルコードスタイルの評価
評価環境を管理する必要性により低下しますが、場合によっては静的機能を簡素化することによって補われることがあります。
3.5.2 リモート評価 (REV)
リモート評価スタイル[50]は、クライアント-サーバーおよび仮想マシンスタイルから派生しており、クライアントコンポーネントはサービスを実行するためのノウハウを持っていますが、必要なリソース(CPUサイクル、データソースなど)が不足しており、それらはリモートサイトに位置しています。その結果、クライアントはノウハウをリモートサイトのサーバーコンポーネントに送信し、サーバーはそこで利用可能なリソースを使用してコードを実行します。その実行の結果はクライアントに送り返されます。リモート評価スタイルは、提供されたコードが保護された環境で実行されることを前提としており、使用されているリソース以外に同じサーバーの他のクライアントに影響を与えないようにします。 リモート評価の利点には、サーバーコンポーネントのサービスをカスタマイズする能力が含まれます。これにより、拡張性とカスタマイズ性が向上し、コードがサーバー内の環境にアクションを適応させることができる場合に効率が向上します(クライアントが同じことをするために一連の相互作用を行うことに比べて)。簡潔さは、評価環境を管理する必要性により低下しますが、
静的サーバー機能を簡素化することにより、いくつかのケースで補償される場合があります。
スケーラビリティは低下します。これは、サーバーが実行環境を管理すること(リソースが逼迫している場合に長時間実行されるコードやリソースを大量に消費するコードを強制終了するなど)で改善できますが、管理機能自体が部分的な障害や信頼性に関する問題を引き起こします。しかし、最も重要な制限は、クライアントが標準化されたクエリではなくコードを送信することによる可視性の欠如です。可視性の欠如は、サーバーがクライアントを信頼できない場合、明らかな展開上の問題を引き起こします。
3.5.3 コードオンデマンド (COD)
コードオンデマンドスタイル [50] では、クライアントコンポーネントは一連のリソースにアクセスできますが、それらを処理する方法に関するノウハウは持ちません。クライアントは、そのノウハウを表すコードをリモートサーバーに要求し、そのコードを受信してローカルで実行します。
コードオンデマンドの利点には、デプロイされたクライアントに機能を追加できること(これにより拡張性と構成性が向上する)、コードがクライアントの環境に合わせて動作を調整し、リモートインタラクションではなくローカルでユーザーとやり取りできる場合にユーザーが感じるパフォーマンスと効率が向上することが含まれます。評価環境を管理する必要性から単純さは低下しますが、クライアントの静的機能を簡素化することで、いくつかのケースで補償される場合があります。サーバーのスケーラビリティは向上します。なぜなら、サーバーはクライアントに作業をオフロードできるため、そのリソースを消費しないからです。リモート評価と同様に、最も重要な制限は、サーバーが単純なデータではなくコードを送信することによる可視性の欠如です。可視性の欠如は、クライアントがサーバーを信頼できない場合、明らかな展開上の問題を引き起こします。
3.5.4 レイヤード・コードオンデマンド・クライアント・キャッシュ・ステートレスサーバー (LCODC$SS)
いくつかのアーキテクチャが補完的であることの例として、前述のレイヤード・クライアント・キャッシュ・ステートレスサーバースタイルにコードオンデマンドを追加することを考えてみましょう。コードは単なる別のデータ要素として扱うことができるため、これはLC$SSスタイルの利点を妨げません。HotJava Webブラウザ [java.sun.com] がその例で、アプレットやプロトコル拡張をタイプメディアとしてダウンロードできます。
LCODC$SSの利点と欠点は、CODとLC$SSの利点と欠点の組み合わせです。さらに、CODと他のCSスタイルの組み合わせについて議論することもできますが、この調査は網羅的(または疲れさせる)ことを意図したものではありません。
3.5.5 モバイルエージェント (MA)
モバイルエージェントスタイル [50] では、計算コンポーネント全体がその状態、必要なコード、およびタスクを実行するために必要なデータとともにリモートサイトに移動します。これはリモート評価とコードオンデマンドスタイルの派生と見なすことができます。なぜなら、モビリティは双方向に機能するからです。
モバイルエージェントスタイルの主な利点は、REVとCODですでに説明されている利点に加えて、コードを移動するタイミングの選択においてより大きなダイナミズムがあることです。アプリケーションは、ある場所で情報を処理している最中に、次の処理したいデータとの距離を縮めるために別の場所に移動することを決定できます。さらに、アプリケーションの状態が一度に1つの場所にあるため、部分的な障害の信頼性問題が軽減されます [50]。
3.6 ピアツーピアスタイル
表 3-5: ネットワークベースのハイパーメディアにおけるピアツーピアスタイルの評価
| スタイル | 派生元 | ネットワーク性能 | ユーザー知覚性能 | 効率性 | スケーラビリティ | シンプルさ | 進化性 | 拡張性 | カスタマイズ性 | 構成可能性 | 再利用性 | 可視性 | 移植性 | 信頼性 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EBI | + | - - | ± | + | + | + | + | - | - | |||||
| C2 | EBI+LCS | - | + | + | ++ | + | + | ++ | ± | + | ± | |||
| DO | CS+CS | - | + | + | + | + | + | - | - | |||||
| BDO | DO+LCS | - | - | ++ | + | + | ++ | - | + |
3.6.1 イベントベース統合(EBI)
イベントベース統合スタイルは、暗黙的呼び出しまたはイベントシステムスタイルとも呼ばれ、コンポーネント間の結合度を低下させます。これは、コネクタインターフェース上の同一性を不要にすることができます。別のコンポーネントを直接呼び出す代わりに、コンポーネントは1つ以上のイベントを宣言(またはブロードキャスト)できます。システム内の他のコンポーネントはその種のイベントに興味を登録することが多く、イベントが宣言されると、システム自体がすべての登録済みコンポーネントを呼び出します[53]。例としては、Smalltalk-80のModel-View-Controllerパラダイム[72]や、Field[113]、SoftBench[29]、Polylith[110]などのさまざまなソフトウェア工学環境の統合メカニズムが挙げられます。イベントベースの統合スタイルは、イベントをリッスンする新しいコンポーネントを容易に追加することで拡張性を強くサポートします。また、一般的なイベントインターフェースと統合メカニズムを奨励することで再利用力を高め、インターフェースを影響させずにコンポーネントを交換できることで進化力を高めます[53]。パイプアンドフィルタシステムのように、「イベントインターフェイス上のイベント配置する見えない手」のために、より高いレベルの構成アーキテクチャが必要です。ほとんどのEBIシステムでは、明示的な呼び出しを補完的な対話形態として含んでいます[53]。データ検索ではなくデータ監視が主なアプリケーションの場合、EBIはポーリング対話の必要性をなくすことで効率を向上させることができます。
EBIシステムの基本形は、すべてのコンポーネントが興味を持つイベントをリッスンする1つのイベントバスで構成されています。もちろん、これはすぐに多数の通知、その通知による他のコンポーネントのブロードキャストによるイベントストーム、通知配信システムの単一障害点に関する拡張性の問題をもたらします。これは、単純さをいくらか犠牲に、レイヤードシステムとイベントフィルタリングを使用することで改善されます。
EBIシステムの他の欠点は、アクションに対する応答が何かを予測するのが難しい(わかりにくい)、イベント通知が粗粒度のデータ交換に適していない[53]ことです。また、いくつかの部分障害からの復旧に対するサポートはありません。
3.6.2 C2
C2アーキテクチャスタイル[128]は、基盤独立性を強制することで、粗粒度の再利用と柔軟なシステムコンポーネントの構成をサポートすることを目的としています。これはイベントベースの統合とレイヤードクライアントサーバーを組み合わせることで実現されます。非同期通知メッセージは下に、非同期リクエストメッセージは上に送信され、コンポーネント間の唯一の通信手段となります。これにより、上位層に対する依存関係の結合度が低くなり(サービスリクエストは無視される可能性がある)、下位レベルとの結合度がゼロになります(通知使用に関する知識なし)。これにより、EBIの利点のほとんどを失うことなく、システムに対する制御が向上します。
通知とは、コンポーネント内の状態変化を示すアナウンスメントです。C2は通知に何を含めるべきかを制約しません。フラグ、状態変化の差異、完全な状態表現などのすべての可能性があります。コネクタの主要な責任はメッセージのルーティングとブロードキャストです。二次的な責任はメッセージフィルタリングです。メッセージのレイヤードフィルタリングの導入は、EBIの問題を拡張性に関して解決し、進化性と再利用性も向上させます。監視機能を含む重量級のコネクタを使用することで、可視性が改善され、部分障害の信頼性問題が軽減されます。
3.6.3 分散オブジェクト
分散オブジェクトスタイルは、システムをピアとして相互作用する一連のコンポーネントとして組織化します。オブジェクトは、いくつかのプライベートな状態情報またはデータ、そのデータを操作する一連の関連操作または手順、および場合によっては制御スレッドをカプセル化するエンティティであり、これらを総合的に1つの単位として考えることができます [31]。一般的に、オブジェクトの状態は完全に隠され、他のすべてのオブジェクトから保護されます。その状態を検査または変更する唯一の方法は、オブジェクトの公開された操作にリクエストまたは呼び出しを行うことです。これにより、各オブジェクトに対して明確に定義されたインターフェースが作成され、オブジェクトの操作の仕様を公開しながら、その操作の実装と状態情報の表現を非公開にすることができ、進化性が向上します。 ある操作が他の操作を呼び出すことがありますが、それは場合によっては他のオブジェクトに対するものである可能性があります。これらの操作は順番に他の呼び出しを行うことがあり、その連鎖はアクションと呼ばれます [31]。状態はオブジェクト間で分散されます。これは、状態を最新の状態に保つために有利ですが、システム全体の活動を把握するのが難しいというデメリットがあります(可視性が低い)。 あるオブジェクトが別のオブジェクトと相互作用するためには、そのオブジェクトの識別子を知っている必要があります。オブジェクトの識別子が変更されると、それを明示的に呼び出すすべての他のオブジェクトを変更する必要があります [53]。アプリケーション要件を完了するために、システム状態を維持する責任を負う何らかのコントローラオブジェクトが必要です。分散オブジェクトシステムの中核的な問題点には、オブジェクト管理、オブジェクト相互作用管理、およびリソース管理が含まれます [31]。 オブジェクトシステムは、処理されるデータを分離するように設計されています。その結果、データストリーミングは一般的にはサポートされていません。ただし、これはモバイルエージェントスタイルと組み合わせた場合に、オブジェクトのモビリティに対してより優れたサポートを提供します。
3.6.4 ブローカード分散オブジェクト
識別子の影響を軽減するために、現代の分散オブジェクトシステムは通常、通信を容易にするために1つ以上の仲介スタイルを使用します。これには、イベントベースの統合とブローカードクライアント/サーバーが含まれます [28]。ブローカード分散オブジェクトスタイルは、名前解決コンポーネントを導入し、その目的は、クライアントオブジェクトの一般的なサービス名に対する要求に応答して、要求を満たす特定のオブジェクトの名前を提供することです。再利用性と進化性を向上させますが、追加のレベルの間接参照が必要であり、ネットワーク相互作用が増え、効率とユーザーが認識するパフォーマンスが低下します。
ブローカード分散オブジェクトシステムは、現在、OMG内のCORBAの産業標準開発 [97] およびISO / IEC内のOpen Distributed Processing(ODP)の国際標準開発 [66] によって支配されています。 分散オブジェクトに関連するすべての関心にもかかわらず、それらは他のほとんどのネットワークベースのアーキテクチャスタイルと比較して低くなります。これらは、ネットワーク相互作用の効率と頻度がそれほど懸念されないハードウェアデバイスなどのカプセル化されたサービスのリモート呼び出しを含むアプリケーションに最適です。
3.7 制限事項
各アーキテクチャスタイルは、コンポーネント間の特定のタイプの相互作用を促進します。コンポーネントが広域ネットワークに分散されている場合、ネットワークの使用または誤用はアプリケーションの使いやすさに影響を与えます。スタイルを、アーキテクチャ特性、特に分散ハイパーメディアシステムのネットワークベースアプリケーションパフォーマンスに対する影響によって特徴付けることで、アプリケーションに適したソフトウェア設計をより適切に選択する能力を得ることができます。ただし、選択した分類にはいくつかの制限があります。
最初の制限は、評価が分散ハイパーメディアのニーズに特化していることです。たとえば、通信が細かな制御メッセージである場合、パイプアンドフィルタスタイルの多くの優れた特性は失われ、通信にユーザーのインタラクティブ性が必要な場合にはまったく適用できません。同様に、クライアント要求に対する応答がキャッシュ可能でない場合、階層化されたキャッシングはレイテンシを増加させるだけで、何のメリットもありません。このような区別は分類には現れず、各スタイルの議論において非公式に扱われています。この制限は、通信問題のタイプごとに別々の分類表を作成することで克服できると考えています。例として、大規模なデータ取得、リモート情報監視、検索、リモート制御システム、分散処理などが挙げられます。
2つ目の制限は、アーキテクチャ特性のグループ化に関するものです。場合によっては、単純さというラベルの下にまとめるのではなく、たとえば理解しやすさや検証可能性などの特定の側面を識別する方が良い場合があります。これは、理解しやすさを犠牲にして検証可能性を向上させる可能性のあるスタイルの場合に特に当てはまります。ただし、特性のより抽象的な概念も単一のメトリックとして価値があります。なぜなら、分類をあまりにも特定しすぎて、2つのスタイルが同じカテゴリに影響を与えないようにするのは望ましくないからです。一つの解決策は、特定の特性と要約特性の両方を提示する分類です。
いずれにせよ、この初期の調査と分類は、その制限に対処する可能性のあるさらなる分類のための必要な前提条件です。
3.8 関連研究
3.8.1 アーキテクチャスタイルとパターンの分類
本章と最も直接的に関連する研究分野は、アーキテクチャスタイルおよびアーキテクチャレベルのパターンの識別と分類である。 Shaw [117]はいくつかのアーキテクチャスタイルを説明し、後にGarlanとShaw [53]で拡張された。これらのスタイルの予備的な分類はShawとClements [122]で提示され、Bassら [9]で繰り返されている。そこでは、制御とデータの問題を主要な軸とした二次元の表形式の分類戦略を使用し、以下の特徴のカテゴリで構成される:スタイルで使用されるコンポーネントとコネクタの種類;コンポーネント間で制御がどのように共有され、割り当てられ、転送されるか;システムを通じてデータがどのように伝達されるか;データと制御がどのように相互作用するか;そして、スタイルと互換性のある推論のタイプ。この分類の主な目的は、スタイルの特徴を識別することであり、それらを比較するためのものではない。それは、設計の指針として「経験則」の小さなセットで締めくくられている。 本章とは異なり、ShawとClements [122]の分類は、アプリケーション設計者にとって有用な方法で設計を評価するのに役立たない。問題は、ソフトウェアを構築する目的が特定の形状、トポロジー、またはコンポーネントタイプを構築することではないため、そのような方法で分類を整理しても、設計者が自分のニーズに対応するスタイルを見つけるのに役立たないことである。また、スタイル間の本質的な違いを、偶発的な重要性しか持たない他の問題と混同し、スタイル間の派生関係を不明瞭にしている。さらに、ネットワークベースのアプリケーションなど、特定のタイプのアーキテクチャに焦点を当てていない。最後に、スタイルをどのように組み合わせるか、またその組み合わせの効果についても説明していない。 BuschmannとMeunier [27]は、パターンを抽象化の粒度、機能性、および構造的な原則に従って整理する分類スキームを説明している。抽象化の粒度は、パターンを3つのカテゴリに分ける:アーキテクチャフレームワーク(アーキテクチャのテンプレート)、デザインパターン、およびイディオム。彼らの分類は、関心の分離やアーキテクチャ特性につながる構造的な原則など、本論文と同じ問題のいくつかを扱っているが、ここで説明されているアーキテクチャスタイルのうち2つしかカバーしていない。彼らの分類は、Buschmannら [28]で大幅に拡張され、アーキテクチャパターンとそのソフトウェアアーキテクチャとの関係に関するより詳細な議論が含まれている。 Zimmer [137]は、デザインパターンをそれらの関係に基づいてグラフで整理し、Gammaら [51]のカタログ内のパターンの全体的な構造を理解しやすくしている。ただし、分類されているパターンはアーキテクチャパターンではなく、分類は建築特性ではなく、派生または使用関係に基づいている。
3.8.2 分散システムとプログラミングパラダイム
Andrews [6]は、分散プログラム内のプロセスがメッセージパッシングを通じてどのように相互作用するかを調査している。彼は、並行プログラム、分散プログラム、分散プログラム内の種類のプロセス(フィルタ、クライアント、サーバー、ピア)、相互作用パラダイム、および通信チャネルを定義している。相互作用パラダイムは、ソフトウェアアーキテクチャスタイルのコミュニケーション側面を表す。彼は、フィルタのネットワークを通じた一方向のデータフロー(パイプアンドフィルタ)、クライアントサーバー、ハートビート、プローブ/エコー、ブロードキャスト、トークンパッシング、複製サーバー、およびタスクのバッグを持つ複製ワーカーのパラダイムを説明している。ただし、このプレゼンテーションは、単一のタスクに協力する複数のプロセスの観点からのものであり、一般的なネットワークベースのアーキテクチャスタイルではない。 SullivanとNotkin [126]は、暗黙の呼び出し研究の調査を提供し、ソフトウェアツールスイートの進化品質を向上させるためのその応用について説明している。
et al. [8] は、比較のためのフレームワークを構築し、その後、いくつかのシステムがそのフレームワークにどのように適合するかを調査することで、イベントベースの統合メカニズムの調査を提示しています。RosenblumとWolf [114] は、インターネット規模のイベント通知のための設計フレームワークを調査しています。これらはすべて、ネットワークベースのシステムのためのソリューションを提供するのではなく、EBIスタイルの範囲と要件に関心を持っています。
Fuggetta et al. [50] は、モバイルコードパラダイムの詳細な調査と分類を提供しています。この章では、モバイルコードスタイルを他のネットワーク対応スタイルと比較し、それらを単一のフレームワークと一連のアーキテクチャ定義に位置付けるという点で、彼らの研究を基にしています。
3.8.3 ミドルウェア
Bernstein [22] は、ミドルウェアを標準的なプログラミングインターフェースとプロトコルを含む分散システムサービスとして定義しています。これらのサービスは、OSやネットワーキングソフトウェアの上であり、業界固有のアプリケーションの下にある層として機能するため、ミドルウェアと呼ばれています。Umar [131] は、この主題に関する広範な扱いを提示しています。
ミドルウェアに関するアーキテクチャ研究は、オフザシェルフのミドルウェアを使用してコンポーネントを統合する際の問題と影響に焦点を当てています。Di NittoとRosenblum [38] は、ミドルウェアと事前定義されたコンポーネントの使用が、開発中のシステムのアーキテクチャにどのように影響を与えるか、そして逆に、特定のアーキテクチャの選択がミドルウェアの選択をどのように制約するかを説明しています。Dashofy et al. [35] は、C2スタイルでのミドルウェアの使用について議論しています。
Garlan et al. [56] は、オフザシェルフのコンポーネント内にあるいくつかのアーキテクチャ上の前提を指摘し、Aesopツールをアーキテクチャ設計のために作成する際に再利用されたサブシステムに関する著者たちの問題を調査しています [54]。彼らは、アーキテクチャのミスマッチに寄与する可能性のある前提を、コンポーネントの性質、コネクタの性質、グローバルなアーキテクチャ構造、および構築プロセスの4つの主要なカテゴリに分類しています。
3.9 まとめ
この章では、ネットワークベースのアプリケーションソフトウェアの一般的なアーキテクチャスタイルを調査し、それらのスタイルを、典型的なネットワークベースのハイパーメディアシステムのアーキテクチャに適用した場合に誘発されるアーキテクチャ特性に基づいて分類するフレームワークを紹介しました。全体の分類を以下の表3-6にまとめます。 次の章では、この調査と分類から得られた知見を活用して、現代のWorld Wide Webアーキテクチャの改善を設計するためのアーキテクチャスタイルを開発および評価する方法を仮説立てます。
表 3-6: 評価のまとめ
| スタイル | 派生元 | ネットワーク性能 | ユーザー知覚性能 | 効率性 | スケーラビリティ | シンプルさ | 進化性 | 拡張性 | カスタマイズ性 | 構成可能性 | 再利用性 | 可視性 | 移植性 | 信頼性 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PF | ± | + | + | + | + | + | ||||||||
| UPF | PF | - | ± | ++ | + | + | ++ | ++ | + | |||||
| RR | ++ | + | + | |||||||||||
| $ | RR | + | + | + | + | |||||||||
| CS | + | + | + | |||||||||||
| LS | - | + | + | + | + | |||||||||
| LCS | CS+LS | - | ++ | + | ++ | + | + | |||||||
| CSS | CS | - | ++ | + | + | + | + | |||||||
| C$SS | CSS+$ | - | + | + | ++ | + | + | + | + | |||||
| LC$SS | LCS+C$SS | - | ± | + | +++ | ++ | ++ | + | + | + | + | |||
| RS | CS | + | - | + | + | - | ||||||||
| RDA | CS | + | - | - | + | - | ||||||||
| VM | ± | + | - | + | ||||||||||
| REV | CS+VM | + | - | ± | + | + | - | + | - | |||||
| COD | CS+VM | + | + | + | ± | + | + | - | ||||||
| LCODC$SS | LC$SS+COD | - | ++ | ++ | +4+ | +±+ | ++ | + | + | + | ± | + | + | |
| MA | REV+COD | + | ++ | ± | ++ | + | + | - | + | |||||
| EBI | + | - - | ± | + | + | + | + | - | - | |||||
| C2 | EBI+LCS | - | + | + | ++ | + | + | ++ | ± | + | ± | |||
| DO | CS+CS | - | + | + | + | + | + | - | - | |||||
| BDO | DO+LCS | - | - | ++ | + | + | ++ | - | + |
第4章
Webアーキテクチャの設計: 問題と洞察
この章では、World Wide Webのアーキテクチャの要件と、その主要な通信プロトコルの改善案を設計および評価する際に直面する問題について説明します。ネットワークベースのハイパーメディアシステムのアーキテクチャスタイルの調査と分類から得られた洞察を活用し、モダンなWebアーキテクチャの改善を導くために使用されるアーキテクチャスタイルを開発する方法を仮説立てます。
4.1 WWW アプリケーションドメインの要件
Berners-Lee [20] は、「Webの主要な目標は、人と機械が通信できる共有情報空間であること」と述べています。必要なのは、人々が永続的または一時的な性質の情報を自分自身と他の人が使用できるように保存および構造化し、他の人が保存した情報を参照および構造化できるようにする方法でした。これにより、誰もがローカルコピーを保持・管理する必要がなくなります。
このシステムの想定エンドユーザーは、インターネット経由で接続された大学や政府の高エネルギー物理学研究所など、世界中に分散していました。
彼らのマシンは、ターミナル、ワークステーション、サーバー、スーパーコンピュータなど多種多様で、様々なオペレーティングシステムソフトウェアとファイルフォーマットが混在していました。
情報は個人の研究ノートから組織の電話帳にまで及びました。課題は、可能な限り多くのプラットフォームで利用可能であり、新しい人や組織がプロジェクトに参加するにつれて段階的に展開できる、構造化された情報に普遍的に一貫したインターフェースを提供するシステムを構築することでした。
4.1.1 低い参入障壁
情報の作成と構造化への参加が任意であるため、十分な普及を可能にするには低い参入障壁が必要でした。これは、Webアーキテクチャのすべてのユーザー(読者、著者、アプリケーション開発者)に当てはまります。
ユーザーインターフェースとしてハイパーメディアが選ばれたのは、そのシンプルさと汎用性のためです。情報源に関係なく同じインターフェースを使用でき、ハイパーメディアの関係(リンク)の柔軟性により無制限の構造化が可能であり、リンクの直接操作により情報内の複雑な関係を利用してアプリケーションを通じて読者を導くことができます。大規模なデータベース内の情報は、ブラウジングよりも検索インターフェースを介してアクセスする方がはるかに簡単であることが多いため、Webはユーザーが入力したデータをサービスに提供し、結果をハイパーメディアとしてレンダリングする簡単なクエリを実行する機能も組み込みました。
著者にとっての主な要件は、システム全体の一部が利用できない場合でも、コンテンツの作成が妨げられてはいけないということでした。ハイパーテキスト作成言語はシンプルで、既存の編集ツールを使用して作成可能である必要がありました。著者は、インターネットに直接接続されているかどうかにかかわらず、個人の研究ノートなどをこの形式で保持することが期待されていたため、参照されている情報が一時的または永久的に利用できない場合でも、利用可能な情報の読み取りや作成が妨げられてはいけませんでした。同じ理由から、参照先が利用可能になる前にその情報への参照を作成できる必要がありました。著者は情報源の開発における協力を奨励されていたため、メールの指示や会議中にナプキンの裏に書かれたものなど、参照を簡単に通信できる必要がありました。
シンプルさはアプリケーション開発者にとっても目標でした。すべてのプロトコルがテキストとして定義されていたため、既存のネットワークツールを使用して通信を表示および対話的にテストできました。これにより、標準が不足しているにもかかわらず、プロトコルの早期採用が可能になりました。
4.1.2 拡張性
シンプルさは分散システムの初期実装を展開することを可能にしますが、拡張性により、展開されたものの制限に永久に縛られることを避けることができます。ユーザーの要件に完全に一致するソフトウェアシステムを構築することができたとしても、社会が変化するのと同じように、それらの要件は時間とともに変化します。Webのように長期間にわたって存続することを意図したシステムは、変化に備える必要があります。
4.1.3 分散型ハイパーメディア
ハイパーメディアは、アプリケーション制御情報が埋め込まれていることによって定義されます。
情報の提示の中、またはその上にレイヤーとして存在します。分散型ハイパーメディアでは、提示と制御情報をリモートの場所に保存することができます。その性質上、分散型ハイパーメディアシステム内でのユーザーのアクションは、データが保存されている場所から使用される場所へ大量のデータを転送する必要があります。したがって、Webアーキテクチャは大規模なデータ転送に対応するように設計されなければなりません。
ハイパーメディアのインタラクションの使いやすさは、ユーザーが感じる遅延(リンクを選択してから使用可能な結果が表示されるまでの時間)に非常に敏感です。Webの情報源はグローバルなインターネットに分散しているため、アーキテクチャはネットワークインタラクション(データ転送プロトコル内の往復通信)を最小限に抑える必要があります。
4.1.4 インターネットスケール
Webは_インターネットスケール_の分散型ハイパーメディアシステムを目指しており、これは単なる地理的な分散をはるかに超えることを意味します。インターネットは、複数の組織の境界を越えて情報ネットワークを相互接続することに関わっています。情報サービスの提供者は、無秩序なスケーラビリティとソフトウェアコンポーネントの独立した展開に対応できなければなりません。
4.1.4.1 無秩序なスケーラビリティ
ほとんどのソフトウェアシステムは、システム全体が1つのエンティティの管理下にあるという暗黙の前提で作成されています。少なくとも、システム内に参加するすべてのエンティティが共通の目標に向かって行動し、互いに矛盾しないという前提です。このような前提は、システムがオープンにインターネット上で動作する場合には安全に適用できません。無秩序なスケーラビリティとは、アーキテクチャ要素が予期しない負荷にさらされた場合や、不正なデータや悪意を持って構築されたデータが与えられた場合にも動作を続ける必要があることを指します。これは、組織の管理外の要素と通信している可能性があるためです。アーキテクチャは、可視性とスケーラビリティを向上させるメカニズムに適合する必要があります。
無秩序なスケーラビリティの要件は、すべてのアーキテクチャ要素に適用されます。クライアントがすべてのサーバーに関する知識を維持することを期待することはできません。サーバーがリクエスト間で状態の知識を保持することを期待することもできません。ハイパーメディアデータ要素は「バックポインタ」(各データ要素がそれらを参照するための識別子)を保持することもできません。なぜなら、リソースへの参照数はその情報に関心を持つ人々の数に比例するからです。特にニュース性の高い情報は、「フラッシュクラウド」につながる可能性もあります:その可用性のニュースが世界中に広まると、アクセス試行が急激に増加します。
アーキテクチャ要素とそれらが動作するプラットフォームのセキュリティも重要な懸念事項となります。複数の組織の境界は、あらゆる通信に複数の信頼境界が存在する可能性があることを意味します。ファイアウォールなどの仲介アプリケーションは、アプリケーションのインタラクションを検査し、組織のセキュリティポリシーの範囲外のものを実行させないようにできる必要があります。アプリケーションのインタラクションに参加する者は、受信した情報が信頼できないと仮定するか、信頼を与える前に追加の認証を要求する必要があります。これには、アーキテクチャが認証データと認可制御を通信できることが必要です。ただし、認証はスケーラビリティを低下させるため、アーキテクチャのデフォルトの動作は、信頼されたデータを必要としないアクションに限定する必要があります:明確に定義されたセマンティクスを持つ安全な操作セットです。
4.1.4.2 独立した展開
複数の組織の境界は、システムが段階的で断片化された変更に備える必要があることも意味します。新旧の実装が共存し、新しい実装がその拡張機能を利用することを妨げないようにする必要があります。既存のアーキテクチャ要素は、後からアーキテクチャ機能が追加されることを期待して設計する必要があります。同様に、古い実装を簡単に識別できるようにして、レガシーな動作をカプセル化し、新しい動作に悪影響を与えないようにする必要があります。
建築要素。全体としてのアーキテクチャは、部分的かつ反復的な方法で建築要素の展開を容易にするように設計されなければなりません。なぜなら、順序だった方法で展開を強制することは不可能だからです。
4.2 問題
1993年後半までに、研究者だけでなく、より多くの人々がWebに関心を持つようになることは明らかでした。Webの採用は最初に小さな研究グループで始まり、キャンパスの寮、クラブ、個人のホームページに広がり、そして後にはキャンパス情報のための機関の部署にまで拡大しました。個人が自分の情報コレクションを、どんなトピックについてでも熱狂的に公開し始めると、ソーシャルネットワーク効果によってウェブサイトの数は指数関数的に増加し、その勢いは現在まで続いています。Webへの商業的な関心は始まったばかりでしたが、国際規模での公開能力がビジネスにとって魅力的であることはすでに明らかでした。
成功に歓喜していたインターネット開発者コミュニティは、Webの利用の急速な成長と、初期のHTTPのいくつかの貧弱なネットワーク特性が、インターネットインフラのキャパシティをすぐに超え、全般的な崩壊を引き起こすのではないかと懸念しました。これは、Web上のアプリケーションインタラクションの性質が変化したことでさらに悪化しました。初期のプロトコルは単一のリクエスト-レスポンスペアのために設計されていましたが、新しいサイトではウェブページのコンテンツの一部としてインラインイメージの数が増加し、ブラウジングのための異なるインタラクションプロファイルが生まれました。展開されたアーキテクチャは拡張性、共有キャッシング、仲介者に対するサポートに大きな制限があり、成長する問題に対するアドホックなソリューションの開発を困難にしていました。同時に、ソフトウェア市場内での商業競争により、Webプロトコルに対する新規で時には矛盾する機能提案が大量に流入しました。
インターネットエンジニアリングタスクフォース内のワーキンググループは、Webの3つの主要な標準であるURI、HTTP、およびHTMLに取り組むために形成されました。これらのグループのチャーターは、初期のWebアーキテクチャで一般的にそして一貫して実装されていた既存のアーキテクチャ通信のサブセットを定義し、そのアーキテクチャ内の問題を特定し、それらの問題を解決するための一連の標準を指定することでした。これは私たちに課題を提示しました:すでに広く展開されているアーキテクチャに新しい機能セットをどのように導入するか、そしてその導入がWebの成功を可能にしたアーキテクチャ特性に悪影響を与えたり、あるいは破壊したりしないようにするにはどうすれば良いか?
4.3 アプローチ
初期のWebアーキテクチャは、関心の分離、シンプルさ、一般性といった堅固な原則に基づいていましたが、アーキテクチャの説明と理論的根拠が欠けていました。設計は、非公式のハイパーテキストノート[14]、ユーザーコミュニティ向けの初期の2つの論文[12, 13]、そしてWeb開発者コミュニティのメーリングリスト(www-talk@info.cern.ch)でアーカイブされた議論に基づいていました。しかし、実際には、初期のWebアーキテクチャの唯一の真の記述は、libwww(クライアントとサーバーのためのCERNプロトコルライブラリ)、Mosaic(NCSAのブラウザクライアント)、そしてそれらと相互運用する他の実装の中に見つけることができました。
アーキテクチャスタイルは、将来のアーキテクチャ設計者が見ることができるように、Webアーキテクチャの背後にある原則を定義するために使用できます。第1章で議論したように、スタイルとは、アーキテクチャ要素に課された制約の名前付きセットであり、それがアーキテクチャに望まれる特性のセットを誘導します。したがって、私のアプローチの最初のステップは、初期のWebアーキテクチャに課された制約を特定し、それが望ましい特性を生み出した理由を明らかにすることです。
さらに、アーキテクチャスタイルに追加の制約を適用することで、インスタンス化されたアーキテクチャに誘導される特性のセットを拡張することができます。私のアプローチの次のステップは、インターネット規模の分散ハイパーメディアシステムに望ましい特性を特定し、それらの特性を誘導する追加のアーキテクチャスタイルを選択し、それらを初期のWeb制約と組み合わせて、現代のWebアーキテクチャのための新しいハイブリッドアーキテクチャスタイルを形成することです。
新しいアーキテクチャスタイルをガイドとして使用することで、Webアーキテクチャに対する提案された拡張や修正をスタイル内の制約と比較することができます。コンフリクトが発生した場合、その提案がWebの設計原則の1つ以上に違反していることを示しています。場合によっては、新しい機能を使用する際に特定のインジケーターを使用することを要求することで、コンフリクトを解消することができます。これは、HTTP拡張で応答のデフォルトのキャッシュ可能性に影響を与える場合によく行われます。重大なコンフリクト、例えばインタラクションスタイルの変更などについては、同じ機能をWebのスタイルに適した設計に置き換えるか、提案者にその機能をWebと並行して実行する別のアーキテクチャとして実装するように指示します。
仮説I : WWWアーキテクチャの設計理論は、Webアーキテクチャ内の要素に適用された制約のセットで構成されるアーキテクチャスタイルで記述できる。
仮説II : WWWアーキテクチャスタイルに制約を追加することで、現代のWebアーキテクチャの望ましい特性をよりよく反映する新しいハイブリッドスタイルを導き出すことができる。
最後に、新しいアーキテクチャスタイルのガイドラインに従って書かれた更新されたプロトコル標準によって定義された更新されたWebアーキテクチャは、Webアプリケーションの大部分を構成するインフラストラクチャーおよびミドルウェアソフトウェアの開発に参加することで展開されます。これには、Apache HTTPサーバープロジェクトやlibwww-perlクライアントライブラリのソフトウェア開発への直接的な参加、およびW3C libwwwやjigsawプロジェクト、Netscape Navigator、Lynx、MSIEブラウザ、そして他の数十の実装の開発者に対してIETFの議論の一部としてアドバイスを行う間接的な参加が含まれていました。 このアプローチを単一のシーケンスとして説明しましたが、実際には非順次的で反復的な方法で適用されています。つまり、過去6年間にわたってモデルを構築し、アーキテクチャスタイルに制約を追加し、クライアントとサーバーソフトウェアに対する実験的な拡張を通じてWebのプロトコル標準への影響をテストしてきました。同様に、他の人々がアーキテクチャに追加することを提案した機能もありましたが、それらは…
当時のモデルスタイルの範囲内で、それと矛盾しない形で進めた結果、改善されたアーキテクチャをより反映するために、アーキテクチャ的な制約を再検討し修正する必要が生じました。目標は常に、Webアーキテクチャがどのように振る舞うべきかについての一貫性のある正確なモデルを維持し、それがプロトコル標準が適切な振る舞いを定義するための指針として使用できるようにすることでした。作業を開始した当初に想像していた制約に縛られた人工的なモデルを作成することではありませんでした。
仮説III : Webアーキテクチャを変更する提案は、更新されたWWWアーキテクチャスタイルと比較し、展開前に矛盾を分析することができる。
4.4 まとめ
この章では、World Wide Webアーキテクチャの要件と、その主要な通信プロトコルに対する改善案を設計および評価する際に直面する問題について説明しました。課題は、改善案を展開する前に評価できるようなアーキテクチャの改善方法を開発することです。私のアプローチは、アーキテクチャスタイルを使用してWebアーキテクチャの背後にある設計理論を定義および改善し、そのスタイルを展開前の拡張案を証明するための厳密なテストとして使用し、Webのインフラストラクチャを作成したソフトウェア開発プロジェクトに直接関与して改訂されたアーキテクチャを展開することです。
次の章では、分散型ハイパーメディアシステムのためのRepresentational State Transfer(REST)アーキテクチャスタイルを紹介し、詳細に説明します。これは、現代のWebがどのように機能すべきかを表すモデルとして開発されました。RESTは、全体として適用された場合、コンポーネント間の相互作用のスケーラビリティ、インターフェースの汎用性、コンポーネントの独立した展開、および相互作用の遅延を減らし、セキュリティを強化し、レガシーシステムをカプセル化するための仲介コンポーネントを強調する一連のアーキテクチャ制約を提供します。
第5章
表現的状態転送 (REST)
この章では、分散ハイパーメディアシステムのための表現的状態転送 (REST) アーキテクチャスタイルを紹介し、詳しく説明します。RESTを導くソフトウェア工学の原則と、それらの原則を維持するために選ばれたインタラクションの制約について説明し、それらを他のアーキテクチャスタイルの制約と対比させます。RESTは、第3章で説明されたいくつかのネットワークベースのアーキテクチャスタイルから派生したハイブリッドスタイルであり、統一されたコネクターインターフェースを定義する追加の制約と組み合わされています。第1章のソフトウェアアーキテクチャフレームワークを使用して、RESTのアーキテクチャ要素を定義し、典型的なアーキテクチャのプロセス、コネクター、データビューのサンプルを検討します。
5.1 RESTの導出
ウェブアーキテクチャの設計原理は、アーキテクチャ内の要素に適用される一連の制約からなるアーキテクチャスタイルによって説明できます。各制約が進化するスタイルに追加される際の影響を検討することで、ウェブの制約によって引き起こされる特性を特定できます。その後、追加の制約を適用して、モダンなウェブアーキテクチャの望ましい特性をよりよく反映する新しいアーキテクチャスタイルを形成できます。このセクションでは、RESTをアーキテクチャスタイルとして導出するプロセスをたどることで、RESTの概要を提供します。後のセクションでは、RESTスタイルを構成する特定の制約についてより詳細に説明します。
5.1.1 Nullスタイルから始める
アーキテクチャ設計のプロセスに対する一般的な視点として、建築物であれソフトウェアであれ、2つの見方があります。1つ目は、設計者が何もない状態(白紙の状態、ホワイトボード、またはドローイングボード)から始め、意図したシステムのニーズを満たすまで、慣れ親しんだコンポーネントを積み上げてアーキテクチャを構築するというものです。2つ目は、設計者がシステムのニーズを全体として、制約なしに開始し、その後、システムの要素に対して制約を段階的に特定して適用することで、設計空間を区別し、システムの動作に影響を与える力をシステムと調和して自然に流れるようにするというものです。前者は創造性と無限のビジョンを強調するのに対し、後者は抑制とシステムの文脈の理解を強調します。RESTは後者のプロセスを使用して開発されました。図5-1から5-8は、適用される制約の集合が段階的に追加されるにつれて、アーキテクチャのプロセスビューがどのように区別されるかをグラフィカルに示しています。
Nullスタイル(図5-1)は、単に空の制約の集合です。アーキテクチャの観点から、Nullスタイルは、コンポーネント間に明確な境界がないシステムを記述します。これは、RESTの説明の出発点です。

5.1.2 クライアント-サーバー
ハイブリッドスタイルに追加される最初の制約は、セクション3.4.1で説明されているクライアント-サーバーアーキテクチャスタイル(図5-2)のものです。関心の分離は、クライアント-サーバーの制約の背後にある原則です。ユーザーインターフェースの関心をデータストレージの関心から分離することで、複数のプラットフォームにわたるユーザーインターフェースの移植性を向上させ、サーバーコンポーネントを簡素化することでスケーラビリティを向上させます。しかし、Webにとって最も重要なのは、この分離によりコンポーネントが独立して進化できることです。これにより、複数の組織ドメインにわたるインターネットスケールの要件をサポートします。

5.1.3 ステートレス
次に、クライアントとサーバーの相互作用に制約を加えます:通信は本質的にステートレスでなければなりません。これは、セクション3.4.3のクライアント-ステートレス-サーバー(CSS)スタイル(図5-3)のように、クライアントからサーバーへの各リクエストには、
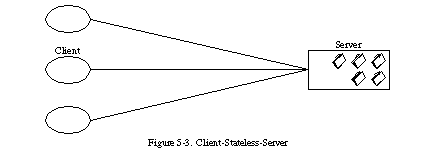
リクエストを理解し、サーバー側に保存されたコンテキストを利用することができません。そのため、セッション状態は完全にクライアント側に保持されます。
この制約により、可視性、信頼性、および拡張性がもたらされます。可視性が向上するのは、監視システムがリクエストの完全な性質を決定するために、単一のリクエストデータ以上を見る必要がないためです。信頼性が向上するのは、部分的な障害からの回復タスクが容易になるためです [133]。拡張性が向上するのは、リクエスト間で状態を保存する必要がないため、サーバーコンポーネントが迅速にリソースを解放でき、さらにサーバーがリクエスト間のリソース使用を管理する必要がないため、実装が簡素化されるためです。
ほとんどのアーキテクチャの選択と同様に、ステートレス制約は設計上のトレードオフを反映しています。欠点は、サーバー側の共有コンテキストにデータを残すことができないため、一連のリクエストで送信される繰り返しデータ(インタラクションごとのオーバーヘッド)が増加し、ネットワークパフォーマンスが低下する可能性があることです。さらに、アプリケーション状態をクライアント側に置くことで、サーバーがアプリケーションの一貫した動作を制御する能力が低下します。これは、アプリケーションが複数のクライアントバージョン間でのセマンティクスの正しい実装に依存するためです。
5.1.4 キャッシュ
ネットワーク効率を向上させるために、キャッシュ制約を追加して、セクション3.4.4(図5-4)のクライアント-キャッシュ-ステートレス-サーバースタイルを形成します。キャッシュ制約では、リクエストに対するレスポンス内のデータが暗黙的または明示的にキャッシュ可能またはキャッシュ不可としてラベル付けされる必要があります。レスポンスがキャッシュ可能である場合、クライアントキャッシュはそのレスポンスデータを後続の同等のリクエストに対して再利用する権利を与えられます。
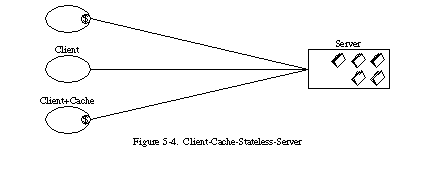
キャッシュ制約を追加する利点は、一部または全てのインタラクションを削減する可能性があり、一連のインタラクションの平均レイテンシを減少させることで、効率、拡張性、およびユーザーが感じるパフォーマンスを向上させることができる点です。しかし、トレードオフとして、キャッシュ内の古いデータが、リクエストが直接サーバーに送信された場合に得られるデータと大きく異なる場合、キャッシュは信頼性を低下させる可能性があります。
図5-5 [11]に示されているように、初期のWebアーキテクチャは、クライアント-キャッシュ-ステートレス-サーバーの制約セットによって定義されていました。つまり、1994年以前のWebアーキテクチャの設計理論は、インターネットを介した静的ドキュメントの交換のためのステートレスなクライアント-サーバーインタラクションに焦点を当てていました。インタラクションを通信するためのプロトコルは、非共有キャッシュの基本的なサポートを提供していましたが、全てのリソースに一貫したセマンティクスのセットをインターフェースに制約しませんでした。代わりに、Webは共通のクライアント-サーバー実装ライブラリ(CERN libwww)を使用して、Webアプリケーション間の一貫性を維持していました。
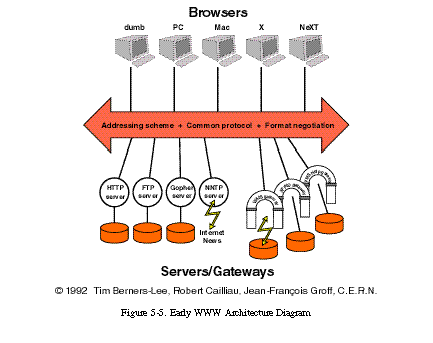
Webの実装開発者は、すでに初期の設計を超えていました。静的なドキュメントに加えて、リクエストは動的にレスポンスを生成するサービスを識別することができました。例えば、イメージマップ [Kevin Hughes] やサーバーサイドスクリプト [Rob McCool] などです。
プロキシ[79]や共有キャッシュ[59]といった中間コンポーネントの開発も始まっていましたが、それらが確実に通信するためにはプロトコルの拡張が必要でした。以下のセクションでは、現代のWebアーキテクチャを形成する拡張を導くために、Webのアーキテクチャスタイルに追加された制約について説明します。
5.1.5 統一インターフェース
RESTアーキテクチャスタイルを他のネットワークベースのスタイルと区別する中心的な特徴は、コンポーネント間の統一インターフェースを重視している点です(図5-6)。コンポーネントインターフェースにソフトウェアエンジニアリングの一般性の原則を適用することで、システム全体のアーキテクチャが簡素化され、相互作用の可視性が向上します。実装は提供するサービスから分離され、これにより
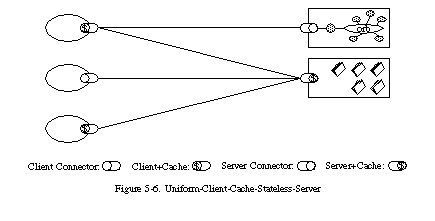
© 1992 ティム・バーナーズ=リー、ロバート・カイリュー、ジャン=フランソワ・グロフ、C.E.R.N.
独立した進化可能性。ただし、トレードオフとして、統一されたインターフェースは効率性を低下させます。なぜなら、情報はアプリケーションのニーズに特化した形式ではなく、標準化された形式で転送されるためです。RESTインターフェースは、大規模なハイパーメディアデータ転送に効率的であるように設計されており、Webの一般的なケースに最適化されていますが、他の形式のアーキテクチャ的相互作用には最適ではないインターフェースを結果をもたらします。
統一されたインターフェースを実現するためには、コンポーネントの動作を導くための複数のアーキテクチャ制約が必要です。RESTは、以下の4つのインターフェース制約によって定義されています:リソースの識別、リソースの表現を通じた操作、自己記述型メッセージ、そしてアプリケーション状態のエンジンとしてのハイパーメディアです。これらの制約については、セクション5.2で説明します。
5.1.6 階層化システム
インターネット規模の要件に対する動作をさらに改善するために、階層化システムの制約を追加します(図5-7)。セクション3.4.2で説明したように、階層化システムスタイルは、各コンポーネントが直接接している階層を超えて「見る」ことができないようにコンポーネントの動作を制約することで、アーキテクチャを階層化された層で構成することを可能にします。
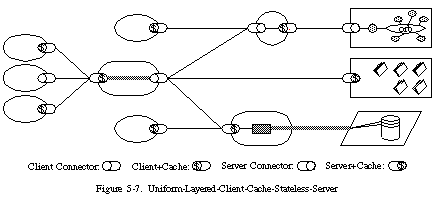
それらは相互作用しています。システムの知識を単一の層に制限することで、全体のシステムの複雑さに境界を設け、基盤の独立性を促進します。レガシーサービスをカプセル化し、新しいサービスをレガシークライアントから保護するために層を使用することで、あまり使用されない機能を共有の中間層に移動することでコンポーネントを簡素化できます。中間層は、複数のネットワークやプロセッサにわたるサービスの負荷分散を可能にすることで、システムのスケーラビリティを向上させるためにも使用できます。
層状システムの主な欠点は、データの処理にオーバーヘッドと遅延を加え、ユーザーが感じるパフォーマンスを低下させることです[32]。キャッシュ制約をサポートするネットワークベースのシステムでは、これを中間層での共有キャッシュの利点で相殺することができます。組織ドメインの境界に共有キャッシュを配置することで、重要なパフォーマンスの向上が得られます[136]。そのような層はまた、ファイアウォールで必要とされるように、組織の境界を越えるデータに対してセキュリティポリシーを適用することを可能にします[79]。
層状システムと統一インターフェース制約の組み合わせは、統一パイプアンドフィルタースタイル(セクション3.2.2)と類似したアーキテクチャ特性を誘発します。RESTの相互作用は双方向ですが、大まかなデータフローは…
ハイパーメディアインタラクションは、データフローネットワークのように処理でき、コンテンツが通過する際にフィルタコンポーネントを選択的に適用してコンテンツを変換することができます[26]。REST内では、メッセージが自己記述的であり、そのセマンティクスが仲介者に対して可視であるため、仲介コンポーネントがメッセージのコンテンツを積極的に変換できます。
5.1.7 コードオンデマンド
RESTの制約セットへの最後の追加は、セクション3.5.3(図5-8)のコードオンデマンドスタイルから来ています。RESTでは、クライアント機能をアプレットやスクリプトの形でコードをダウンロードして実行することで拡張できます。これにより、事前に実装が必要な機能の数を減らすことでクライアントが簡素化されます。デプロイ後に機能をダウンロードできるようにすることで、システムの拡張性が向上します。ただし、これにより可視性が低下するため、REST内ではオプションの制約に過ぎません。
オプションの制約という概念は、一見矛盾しているように見えるかもしれません。しかし、複数の組織の境界を包含するシステムのアーキテクチャ設計において目的を持っています。これは、アーキテクチャがその利点を得る(そして
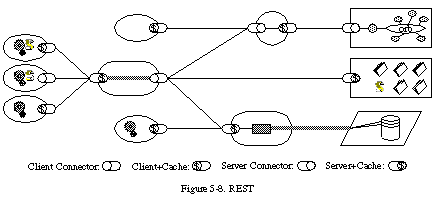
全体的なシステムの一部の領域で有効であることがわかっている場合、オプションの制約の利点(および欠点)を利用することができます。たとえば、組織内のすべてのクライアントソフトウェアがJavaアプレットをサポートしていることがわかっている場合 [45]、その組織内のサービスは、ダウンロード可能なJavaクラスを通じて機能強化の利点を得るように構築することができます。しかし同時に、組織のファイアウォールが外部からのJavaアプレットの転送を防ぐ可能性があり、その結果、それ以外のWebに対しては、それらのクライアントがコードオンデマンドをサポートしていないように見えることになります。オプションの制約を使用することで、一般的なケースで望ましい動作をサポートするアーキテクチャを設計できますが、一部のコンテキストでは無効になる可能性があることを理解しておくことができます。
5.1.8 スタイルの導出の概要
RESTは、候補となるアーキテクチャに誘発する特性のために選択された一連のアーキテクチャ制約で構成されています。これらの制約はそれぞれ個別に考慮することができますが、それらを一般的なアーキテクチャスタイルから導出されたものとして説明することで、選択の背後にある理論を理解しやすくするためです。図5-9は、第3章で検討したネットワークベースのアーキテクチャスタイルの観点から、RESTの制約の導出を図示しています。
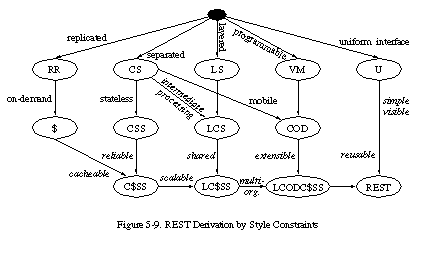
Representational State Transfer(REST)スタイルは、分散型ハイパーメディアシステム内のアーキテクチャ要素の抽象化です。RESTは、コンポーネントの実装の詳細やプロトコルの構文を無視し、コンポーネントの役割、他のコンポーネントとの相互作用に対する制約、および重要なデータ要素の解釈に焦点を当てます。これには、Webアーキテクチャの基礎を定義するコンポーネント、コネクタ、およびデータに対する基本的な制約が含まれ、ネットワークベースのアプリケーションとしてのその動作の本質を表します。
5.2.1 データ要素
分散オブジェクトスタイル[31]では、すべてのデータが処理コンポーネント内にカプセル化され隠されていますが、RESTではアーキテクチャのデータ要素の性質と状態が重要な側面です。この設計の根拠は、分散型ハイパーメディアの性質に見ることができます。リンクが選択されると、情報はその保存場所から、ほとんどの場合、人間の読者が使用する場所に移動する必要があります。これは、他の多くの分散処理パラダイム[6, 50]とは異なり、データをプロセッサに移動するのではなく、「処理エージェント」(例えば、モバイルコード、ストアドプロシージャ、検索式など)をデータに移動することが可能であり、通常はより効率的です。分散型ハイパーメディアアーキテクトには、基本的に3つの選択肢があります:1)データをその場所でレンダリングし、固定形式の画像を受信者に送信する;2)レンダリングエンジンでデータをカプセル化し、両方を受信者に送信する;または、3)生データをデータ型を説明するメタデータとともに受信者に送信し、受信者が独自のレンダリングエンジンを選択できるようにする。
各オプションには利点と欠点があります。オプション1、従来のクライアント-サーバースタイル[31]では、データの真の性質に関するすべての情報が送信者内に隠されたままになり、データ構造についての仮定が行われず、クライアントの実装が容易になります。しかし、受信者の機能を大幅に制限し、処理負荷の大部分を送信者に負わせるため、スケーラビリティの問題が発生します。オプション2、モバイルオブジェクトスタイル[50]では、情報の隠蔽を提供し、独自のレンダリングエンジンによるデータの特殊な処理を可能にしますが、受信者の機能をそのエンジン内で予想されるものに制限し、転送されるデータ量を大幅に増加させる可能性があります。オプション3では、送信者がシンプルでスケーラブルなまま、転送されるバイト数を最小限に抑えることができますが、情報の隠蔽の利点を失い、送信者と受信者が同じデータ型を理解する必要があります。
RESTは、メタデータによるデータ型の共有理解に焦点を当てながら、標準化されたインターフェースに公開される範囲を制限することで、これら3つのオプションのハイブリッドを提供します。RESTコンポーネントは、リソースの表現を、受信者の能力や希望、およびリソースの性質に基づいて動的に選択される進化する標準データ型の1つに一致する形式で転送することによって通信します。表現が生のソースと同じ形式であるか、ソースから派生したものであるかは、インターフェースの背後に隠されています。モバイルオブジェクトスタイルの利点は、カプセル化されたレンダリングエンジン(例:Java[45])の標準データ形式での指示で構成される表現を送信することで近似されます。したがって、RESTは、サーバーのスケーラビリティ問題なしにクライアント-サーバースタイルの関心の分離を実現し、サービスのカプセル化と進化を可能にする汎用インターフェースを通じて情報の隠蔽を可能にし、ダウンロード可能な機能エンジンを通じて多様な機能セットを提供します。
RESTのデータ要素は、表5-1にまとめられています。
| Data Element | Modern Web Examples |
|---|---|
| resource | the intended conceptual target of a hypertext reference |
| resource identifier | URL, URN |
| representation | HTML document, JPEG image |
| representation metadata | media type, last-modified time |
| resource metadata | source link, alternates, vary |
| control data | if-modified-since, cache-control |
5.2.1.1 リソースとリソース識別子
RESTにおける情報の重要な抽象化は リソース です。名前を付けられるものは何でもリソースになり得ます。例えば、ドキュメントや画像、一時的なサービス(例:「ロサンゼルスの今日の天気」)、他のリソースのコレクション、非仮想オブジェクト(例:人物)などです。言い換えれば、著者のハイパーテキスト参照のターゲットとなり得る概念は、リソースの定義に適合しなければなりません。リソースとは、エンティティの集合への概念的なマッピングであり、特定の時点でマッピングに対応するエンティティそのものではありません。
より正確には、リソース R は時間的に変化するメンバーシップ関数 MR(t) であり、時間 t において、等価なエンティティまたは値のセットにマッピングします。セット内の値は、リソース表現 や リソース識別子 である場合があります。リソースは空のセットにマッピングすることも可能であり、これにより、その概念が実現される前にその概念への参照を作成できます。これは、Web以前のほとんどのハイパーテキストシステムにはなかった考え方です[61]。作成後どの時点で見ても常に同じ値セットに対応するという意味で、静的であるリソースもあります。一方、時間とともに値が大きく変化するリソースもあります。リソースに対して静的であることが求められる唯一のものはマッピングのセマンティクスで、セマンティクスこそが、他のリソースとの区別を可能にします。
例えば、学術論文の「著者が推奨するバージョン」は、時間とともにその値が変化するマッピングですが、「学会Xの議事録に掲載された論文」へのマッピングは静的です。これらは2つの異なるリソースであり、たとえある時点で両者が同じ値にマッピングされる場合でもそうです。この区別は、両方のリソースを個別に識別および参照できるようにするために必要です。ソフトウェアエンジニアリングにおける類似の例として、バージョン管理されたソースコードファイルを参照する際に、「最新リビジョン」「リビジョン番号1.2.7」「Orangeリリースに含まれるリビジョン」などの個別の識別があります。
このリソースの抽象的な定義は、Webアーキテクチャの重要な機能を可能にします。まず、情報源をタイプや実装によって人為的に区別することなく、多くの情報源を包含することにより、汎用性を提供します。第二に、表現への参照を遅延バインドできるため、リクエストの特性に基づいてコンテンツネゴシエーションを行うことが可能になります。最後に、著者はその概念の特定の表現ではなく、概念自体を参照することができるため、表現が変更されるたびに既存のすべてのリンクを変更する必要がなくなります(著者が正しい識別子を使用していると仮定します)。
RESTは、コンポーネント間の相互作用に関与する特定のリソースを識別するために リソース識別子 を使用します。RESTコネクタは、リソースの値セットにアクセスおよび操作するための汎用インターフェースを提供し、メンバーシップ関数がどのように定義されているか、またはリクエストを処理するソフトウェアのタイプに関係なく機能します。リソース識別子を割り当て、リソースを参照可能にする命名機関は、時間の経過とともにマッピングのセマンティックな妥当性を維持する責任があります(つまり、メンバーシップ関数が変更されないことを保証します)。
伝統的なハイパーテキストシステム[61]は、通常、閉じたまたはローカル環境で動作し、情報が変更されるたびに一意のノードまたはドキュメント識別子を変更し、リンクサーバーに依存してコンテンツとは別に参照を維持します[135]。しかし、中央集権的なリンクサーバーは、Webの巨大なスケールと複数の組織ドメインの要件には相性が悪いため、RESTは代わりに著者に依存します。
識別する概念の性質に最も適したリソース識別子を選択する。
当然ながら、識別子の品質は、その有効性を維持するために費やされる金額に比例することが多く、これにより、一時的(または十分にサポートされていない)情報が時間の経過とともに移動または消滅するにつれて、リンク切れが発生します。
5.2.1.2 表現
RESTコンポーネントは、リソースの現在または意図された状態をキャプチャし、その表現をコンポーネント間で転送することによって、リソースに対するアクションを実行します。_表現_とは、バイト列と、それらのバイトを説明する_表現メタデータ_のことです。表現の一般的だが正確でない呼び方としては、ドキュメント、ファイル、HTTPメッセージエンティティ、インスタンス、またはバリアントがあります。
表現は、データ、データを説明するメタデータ、および場合によってはメタデータを説明するメタデータ(通常はメッセージの整合性を検証するため)で構成されます。メタデータは名前と値のペアの形式であり、名前は値の構造とセマンティクスを定義する標準に対応します。レスポンスメッセージには、表現メタデータと_リソースメタデータ_(提供された表現に固有でないリソースに関する情報)の両方が含まれる場合があります。
_制御データ_は、コンポーネント間のメッセージの目的(リクエストされているアクションやレスポンスの意味など)を定義します。また、リクエストをパラメータ化したり、一部の接続要素のデフォルトの動作をオーバーライドするためにも使用されます。たとえば、キャッシュの動作は、リクエストまたはレスポンスメッセージに含まれる制御データによって変更できます。
メッセージの制御データに応じて、特定の表現は、リクエストされたリソースの現在の状態、リクエストされたリソースの望ましい状態、またはクライアントのクエリフォーム内の入力データの表現や、レスポンスのエラー状態の表現など、他のリソースの値を示すことがあります。たとえば、リソースのリモート作成では、作成者がサーバーに表現を送信し、それによって後続のリクエストで取得できるリソースの値を設定する必要があります。特定の時点でのリソースの値セットが複数の表現で構成されている場合、コンテンツネゴシエーションを使用して、特定のメッセージに含める最適な表現を選択できます。
表現のデータ形式は_メディアタイプ_ [48]として知られています。表現はメッセージに含めることができ、受信者はメッセージの制御データとメディアタイプの性質に従って処理します。一部のメディアタイプは自動処理を目的とし、一部はユーザーが閲覧するためのレンダリングを目的とし、いくつかはその両方を可能にします。複合メディアタイプを使用して、単一のメッセージ内に複数の表現を囲むことができます。
メディアタイプの設計は、分散ハイパーメディアシステムのユーザーが感じるパフォーマンスに直接影響を与える可能性があります。受信者が表現のレンダリングを開始する前に受信しなければならないデータは、インタラクションの遅延を増加させます。最も重要なレンダリング情報を先頭に配置し、残りの情報が受信されている間にも初期情報を段階的にレンダリングできるデータ形式は、レンダリングを開始する前に完全に受信しなければならないデータ形式よりも、ユーザーが感じるパフォーマンスが大幅に向上します。
たとえば、大きなHTMLドキュメントを受信しながら段階的にレンダリングできるウェブブラウザは、ドキュメントが完全に受信されるまでレンダリングを待つブラウザよりも、ネットワークパフォーマンスが同じであっても、ユーザーが感じるパフォーマンスが大幅に向上します。表現のレンダリング能力は、コンテンツの選択によっても影響を受けることに注意してください。動的にサイズが決まるテーブルや埋め込みオブジェクトの寸法をレンダリング前に決定する必要がある場合、それらがハイパーメディアページの表示領域内に現れると、その遅延が増加します。
5.2.2 コネクタ
RESTは、表5-2にまとめられているさまざまなコネクタタイプを使用して、アクティビティをカプセル化します。
| Connector | Modern Web Examples |
|---|---|
| client | libwww, libwww-perl |
| server | libwww, Apache API, NSAPI |
| cache | browser cache, Akamai cache network |
| resolver | bind (DNS lookup library) |
| tunnel | SOCKS, SSL after HTTP CONNECT |
リソースへのアクセスとリソース表現の転送を行うためのものです。コネクタは、コンポーネント間の通信のための抽象インターフェースを提供し、関心の分離を明確にし、リソースと通信メカニズムの基盤となる実装を隠すことで、シンプルさを高めます。このインターフェースの汎用性により、置換可能性も実現されます。つまり、ユーザーがシステムにアクセスする唯一の手段が抽象インターフェースである場合、実装を変更してもユーザーに影響を与えることはありません。コネクタはコンポーネントのネットワーク通信を管理するため、効率と応答性を向上させるために、複数のインタラクション間で情報を共有することができます。
すべてのRESTインタラクションはステートレスです。つまり、各リクエストには、コネクタがリクエストを理解するために必要なすべての情報が含まれており、以前のリクエストに依存しません。この制約により、以下の4つの機能が実現されます。1) コネクタがリクエスト間でアプリケーションの状態を保持する必要がなくなり、物理リソースの消費が減少し、スケーラビリティが向上します。2) インタラクションを並列で処理できるようになり、処理メカニズムがインタラクションのセマンティクスを理解する必要がなくなります。3) サービスが動的に再編成される場合に必要となるかもしれない、中間者がリクエストを単独で表示および理解できるようになります。4) キャッシュされたレスポンスの再利用性に影響を与える可能性のあるすべての情報が、各リクエストに含まれることが保証されます。
コネクタインターフェースはプロシージャ呼び出しに似ていますが、パラメータと結果の渡し方に重要な違いがあります。入力パラメータには、リクエスト制御データ、リクエストのターゲットを示すリソース識別子、およびオプションの表現が含まれます。出力パラメータには、レスポンス制御データ、オプションのリソースメタデータ、およびオプションの表現が含まれます。抽象的な視点では、呼び出しは同期的ですが、入力パラメータと出力パラメータの両方をデータストリームとして渡すことができます。つまり、パラメータの値が完全にわかる前に処理を呼び出すことができ、大きなデータ転送をバッチ処理する際の遅延を回避できます。
主なコネクタのタイプはクライアントとサーバーです。両者の本質的な違いは、_クライアント_がリクエストを行うことで通信を開始するのに対し、_サーバー_は接続を待ち受け、リクエストに応答してサービスへのアクセスを提供する点です。コンポーネントはクライアントとサーバーの両方のコネクタを含むことがあります。
第三のコネクタタイプである_キャッシュ_コネクタは、クライアントまたはサーバーコネクタのインターフェースに配置され、現在のインタラクションに対するキャッシュ可能なレスポンスを保存し、後で要求されるインタラクションに再利用できるようにします。クライアントがネットワーク通信の繰り返しを避けるためにキャッシュを使用する場合や、サーバーがレスポンスを生成するプロセスを繰り返すのを避けるために使用する場合があり、どちらの場合もインタラクションの遅延を減少させます。キャッシュは通常、それを使用するコネクタのアドレス空間内に実装されます。
一部のキャッシュコネクタは共有されており、そのキャッシュされたレスポンスは、元々レスポンスを取得したクライアント以外のクライアントに対する応答として使用されることがあります。共有キャッシュは、特に企業のイントラネット内のユーザーグループや、インターネットサービスプロバイダの顧客、または国立ネットワークバックボーンを共有する大学など、大規模なユーザーグループをカバーするために階層的に配置された場合に、人気のあるサーバーに対する「フラッシュクラウド」の影響を軽減するのに効果的です。しかし、キャッシュされたレスポンスが新しいリクエストで得られるものと一致しない場合、共有キャッシュはエラーを引き起こす可能性もあります。RESTは、キャッシュの動作の透明性を求める欲求と、ネットワークの効率的な使用を求める欲求のバランスを取ろうとしており、
絶対的な透明性が常に必要とされます。
キャッシュは、インターフェースが各リソース固有ではなく汎用的であるため、レスポンスのキャッシュ可能性を判断できます。デフォルトでは、取得リクエストに対するレスポンスはキャッシュ可能であり、他のリクエストに対するレスポンスはキャッシュ不可です。リクエストに何らかのユーザー認証が含まれている場合、またはレスポンスが共有すべきでないことを示している場合、そのレスポンスは非共有キャッシュでのみキャッシュ可能です。コンポーネントは、インタラクションをキャッシュ可能、キャッシュ不可、または限られた時間のみキャッシュ可能とマークする制御データを含めることで、これらのデフォルトを上書きできます。
リゾルバー は、部分的なまたは完全なリソース識別子を、コンポーネント間の接続を確立するために必要なネットワークアドレス情報に変換します。たとえば、ほとんどのURIには、リソースの命名権限を識別するためのメカニズムとしてDNSホスト名が含まれています。Webブラウザは、リクエストを開始するためにURIからホスト名を抽出し、DNSリゾルバーを使用してその権限のインターネットプロトコルアドレスを取得します。別の例として、いくつかの識別スキーム(例:URN[124])では、識別されたリソースにアクセスするために、永続的な識別子をより一時的なアドレスに変換する仲介者が必要です。1つ以上の仲介リゾルバーを使用することで、間接化を通じてリソース参照の長寿命化が可能ですが、リクエストの待ち時間が増加します。
最後のコネクタタイプは トンネル です。トンネルは、ファイアウォールや下位レベルのネットワークゲートウェイなどの接続境界を越えて通信を中継します。これがRESTの一部としてモデル化され、ネットワークインフラの一部として抽象化されない唯一の理由は、一部のRESTコンポーネントが動的にアクティブなコンポーネントの動作からトンネルの動作に切り替える可能性があるためです。主な例は、CONNECTメソッドリクエスト[71]に応答してトンネルに切り替えるHTTPプロキシで、これによりクライアントはプロキシを許可しないTLSなどの異なるプロトコルを使用してリモートサーバーと直接通信できるようになります。トンネルは、両端が通信を終了すると消えます。
5.2.3 コンポーネント
RESTコンポーネントは、表5-3にまとめられているように、アプリケーション全体のアクションにおける役割によって分類されます。
| Component | Modern Web Examples |
|---|---|
| origin server | Apache httpd, Microsoft IIS |
| gateway | Squid, CGI, Reverse Proxy |
| proxy | CERN Proxy, Netscape Proxy, Gauntlet |
| user agent | Netscape Navigator, Lynx, MOMspider |
ユーザーエージェント は、クライアントコネクタを使用してリクエストを開始し、レスポンスの最終的な受信者になります。最も一般的な例はWebブラウザで、情報サービスへのアクセスを提供し、アプリケーションのニーズに応じてサービスレスポンスをレンダリングします。
オリジンサーバー は、サーバーコネクタを使用して、リクエストされたリソースの名前空間を管理します。これはリソースの表現の確定的なソースであり、リソースの値を変更することを意図したリクエストの最終的な受信者でなければなりません。各オリジンサーバーは、リソース階層としてサービスへの汎用的なインターフェースを提供します。リソースの実装詳細はインターフェースの背後に隠されています。
仲介コンポーネントは、クライアントとサーバーの両方として動作し、可能な翻訳を伴ってリクエストとレスポンスを転送します。プロキシ コンポーネントは、クライアントによって選択された仲介者で、他のサービスのインターフェースカプセル化、データ翻訳、パフォーマンス向上、またはセキュリティ保護を提供します。ゲートウェイ(別名、リバースプロキシ)コンポーネントは、ネットワークまたはオリジンサーバーによって課される仲介者で、他のサービスのインターフェースカプセル化、データ翻訳、パフォーマンス向上、またはセキュリティ強化を提供します。プロキシとゲートウェイの違いは、プロキシを使用するタイミングをクライアントが決定することです。
表5-3. RESTコンポーネント
コンポーネント 現代のWeb例
オリジンサーバー Apache httpd, Microsoft IIS
ゲートウェイ Squid, CGI, リバースプロキシ
プロキシ CERN Proxy, Netscape Proxy, Gauntlet
ユーザーエージェント Netscape Navigator, Lynx, MOMspider
5.3 RESTアーキテクチャビュー
RESTアーキテクチャの要素を個別に理解したところで、アーキテクチャビュー[105]を使用して、これらの要素がどのように連携してアーキテクチャを形成するかを説明できます。プロセスビュー、コネクタビュー、データビューの3種類のビューが、RESTの設計原則を明らかにするのに役立ちます。
5.3.1 プロセスビュー
アーキテクチャのプロセスビューは、システム内をデータが流れる経路を明らかにすることで、コンポーネント間の相互作用関係を引き出すのに主に効果的です。残念ながら、実際のシステムの相互作用は通常、多数のコンポーネントが関与するため、詳細に隠されて全体像が不明瞭になることがあります。
図5-10は、3つの並列リクエストが処理されている特定の瞬間におけるRESTベースのアーキテクチャのプロセスビューの例を示しています。 RESTのクライアント-サーバーの関心の分離により、コンポーネントの実装が簡素化され、コネクタセマンティクスの複雑さが軽減され、パフォーマンスチューニングの効果が向上し、純粋なサーバーコンポーネントのスケーラビリティが高まります。レイヤードシステムの制約により、プロキシ、ゲートウェイ、ファイアウォールなどの仲介者が通信のさまざまなポイントに導入されても、コンポーネント間のインターフェースが変更されないため、通信の翻訳を支援したり、大規模な共有キャッシュを介してパフォーマンスを向上させたりすることが可能です。RESTは、メッセージが自己記述的であるように制約を設けることで、中間処理を可能にします。リクエスト間での相互作用はステートレスであり、
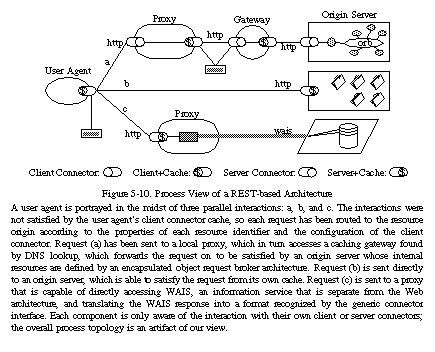
ユーザーエージェントは、3つの並列インタラクション(a、b、c)の最中に描かれています。これらのインタラクションはユーザーエージェントのクライアントコネクタキャッシュでは満たされなかったため、各リクエストはリソース識別子のプロパティとクライアントコネクタの構成に従って資源オリジンにルーティングされました。リクエスト(a)はローカルプロキシに送信され、そのプロキシはDNSルックアップによって見つかったキャッシングゲートウェイにアクセスし、そのゲートウェイはリクエストをカプセル化されたオブジェクトリクエストブローカーアーキテクチャによって定義された内部リソースを持つオリジンサーバーに転送します。リクエスト(b)はオリジンサーバーに直接送信され、そのサーバーは自身のキャッシュからリクエストを満たすことができます。リクエスト(c)は、Webアーキテクチャとは別の情報サービスであるWAISに直接アクセスし、WAISのレスポンスを汎用コネクタインターフェースで認識可能な形式に変換できるプロキシに送信されます。各コンポーネントは、自身のクライアントまたはサーバーコネクタとのインタラクションのみを認識しています。全体のプロセストポロジは、このビューの産物です。
標準的なメソッドとメディアタイプは、セマンティクスを示し情報を交換するために使用され、レスポンスは明示的にキャッシュ可能性を示します。 コンポーネントは動的に接続されるため、特定のアプリケーションアクションに対するそれらの配置と機能は、パイプアンドフィルタスタイルに似た特性を持ちます。RESTコンポーネントは双方向ストリームを介して通信しますが、各方向の処理は独立しており、ストリームトランスデューサ(フィルタ)の影響を受けやすくなっています。汎用コネクタインターフェースにより、各リクエストまたはレスポンスのプロパティに基づいてストリーム上にコンポーネントを配置することが可能です。 サービスは、複雑な階層を持つインターミディエリと複数の分散オリジンサーバーを使用して実装されることがあります。RESTのステートレスな性質により、各インタラクションは他のインタラクションから独立しており、インターネット規模のアーキテクチャでは不可能な全体のコンポーネントトポロジを認識する必要がなく、各リクエストのターゲットに基づいて動的に目的または仲介役として機能することを可能にします。コネクタは、通信のスコープ内で互いの存在を認識するだけでよく、パフォーマンス上の理由から他のコンポーネントの存在と機能をキャッシュすることがあります。
5.3.2 コネクタビュー
アーキテクチャのコネクタビューは、コンポーネント間の通信のメカニズムに焦点を当てます。RESTベースのアーキテクチャでは、特に汎用リソースインターフェースを定義する制約に興味があります。 クライアントコネクタは、各リクエストに対して適切な通信メカニズムを選択するためにリソース識別子を調べます。たとえば、識別子がローカルリソースを示す場合、特定のプロキシコンポーネント(注釈フィルタとして機能するものなど)に接続するようにクライアントを設定できます。同様に、クライアントは、識別子の一部のサブセットに対するリクエストを拒否するように設定できます。 RESTは通信を特定のプロトコルに制限しませんが、コンポーネント間のインターフェースを制約するため、コンポーネント間で作られる可能性のあるインタラクションの範囲と実装の前提を制限します。たとえば、Webの主要な転送プロトコルはHTTPですが、このアーキテクチャには、FTP [107]、Gopher [7]、WAIS [36]などの既存のネットワークサーバーに由来するリソースへのシームレスなアクセスも含まれます。これらのサービスとのインタラクションは、RESTコネクタのセマンティクスに制限されます。この制約は、WAISのような関連性フィードバックプロトコルのステートフルなインタラクションなどの他のアーキテクチャの利点の一部を犠牲にして、コネクタセマンティクスのための単一の汎用インターフェースの利点を保持します。その代わりに、汎用
インターフェースは、単一のプロキシを通じて多数のサービスにアクセスすることを可能にします。アプリケーションが別のアーキテクチャの追加機能を必要とする場合、それらの機能を並行して実行される別のシステムとして実装し、呼び出すことができます。これは、Webアーキテクチャが「telnet」や「mailto」リソースとインターフェースする方法に似ています。
5.3.3 データビュー
アーキテクチャのデータビューは、情報がコンポーネント間を流れる際のアプリケーションの状態を明らかにします。RESTは特に分散情報システムを対象としているため、アプリケーションを、ユーザーが目的のタスクを実行できる情報と制御の選択肢の一貫した構造として見なします。たとえば、オンライン辞書で単語を調べることは1つのアプリケーションであり、架空の美術館を巡ったり、試験勉強のためにクラスのノートを確認したりすることもアプリケーションです。各アプリケーションは、システムのパフォーマンスを測定するための目標を定義します。
コンポーネント間の相互作用は、動的にサイズが変化するメッセージの形式で行われます。小さなまたは中程度の粒度のメッセージは制御セマンティクスに使用されますが、アプリケーション作業の大部分は、完全なリソース表現を含む大きな粒度のメッセージによって達成されます。最も頻繁に使用されるリクエストセマンティクスは、リソースの表現を取得するためのものであり(例:HTTPの「GET」メソッド)、キャッシュして後で再利用できることがよくあります。
RESTは、すべての制御状態を、相互作用への応答として受け取った表現に集中させます。これにより、サーバーが現在のリクエストを超えてクライアントの状態を把握する必要をなくすことで、サーバーのスケーラビリティを向上させることが目的です。したがって、アプリケーションの状態は、保留中のリクエスト、接続されたコンポーネントのトポロジ(その一部はバッファリングされたデータをフィルタリングしている可能性があります)、それらのコネクタ上のアクティブなリクエスト、それらのリクエストへの応答としての表現のデータフロー、およびユーザーエージェントがそれらの表現を受け取った際の処理によって定義されます。
アプリケーションは、保留中のリクエストがなく、現在のリクエストセットに対するすべての応答が完全に受信された、または表現データストリームとして扱える状態に達した場合、定常状態に達します。ブラウザアプリケーションの場合、この状態は「ウェブページ」に対応し、主要な表現と、インライン画像、埋め込まれたアプレット、スタイルシートなどの補助的な表現が含まれます。アプリケーションの定常状態の重要性は、ユーザーが認識するパフォーマンスとネットワークリクエストトラフィックの突発性に対する影響に見られます。
ブラウザアプリケーションのユーザーが認識するパフォーマンスは、定常状態間の遅延、つまり1つのウェブページでハイパーメディアリンクが選択されてから次のウェブページで使用可能な情報が表示されるまでの時間によって決まります。したがって、ブラウザのパフォーマンスの最適化は、この通信遅延を減らすことに焦点を当てています。
RESTベースのアーキテクチャは、主にリソースの表現の転送を通じて通信するため、遅延は通信プロトコルの設計と表現データフォーマットの設計の両方に影響を受けます。受信した応答データを段階的にレンダリングする能力は、メディアタイプの設計と各表現内のレイアウト情報(インラインオブジェクトの視覚的寸法)の可用性によって決まります。
興味深い観察は、最も効率的なネットワークリクエストは、ネットワークを使用しないリクエストであるということです。言い換えると、キャッシュされた応答を再利用できる能力は、アプリケーションパフォーマンスの大幅な向上をもたらします。キャッシュの使用により、各リクエストにルックアップのオーバーヘッドが追加されるため、わずかな遅延が発生しますが、リクエストのごく一部が使用可能なキャッシュヒットになるだけで、平均リクエスト遅延は大幅に減少します。
アプリケーションの次の制御状態は、最初の表現に存在します。
リクエストされたリソースを取得するため、最初の表現を取得することが優先事項です。したがって、RESTの相互作用は「まず応答し、後で考える」プロトコルによって改善されます。言い換えれば、コンテンツの応答を送信する前に機能の能力をネゴシエートするなど、ユーザーアクションごとに複数の相互作用を必要とするプロトコルは、最初に最適と思われるものを送信し、最初の応答が不十分な場合にクライアントが取得できる代替案のリストを提供するプロトコルよりも、認識的に遅く感じられるでしょう。
アプリケーションの状態はユーザーエージェントによって制御および保存され、複数のサーバーからの表現で構成することができます。これにより、サーバーは状態を保存するスケーラビリティの問題から解放されるだけでなく、ユーザーが直接状態を操作すること(例:ウェブブラウザの履歴)、その状態の変更を予測すること(例:リンクマップや表現のプリフェッチ)、およびあるアプリケーションから別のアプリケーションにジャンプすること(例:ブックマークやURI入力ダイアログ)が可能になります。
したがって、モデルアプリケーションは、現在の表現セット内の代替状態遷移を調べ、選択することによって、ある状態から次の状態に移動するエンジンです。当然ながら、これはハイパーメディアブラウザのユーザーインターフェースと完全に一致します。ただし、このスタイルでは、すべてのアプリケーションがブラウザであると仮定していません。実際、アプリケーションの詳細は汎用コネクタインターフェースによってサーバーから隠されており、したがって、ユーザーエージェントは、インデックスサービスのための情報検索を行う自動化されたロボット、特定の基準に一致するデータを探す個人エージェント、または壊れた参照や変更されたコンテンツを監視するメンテナンススパイダーでもあり得ます[39]。
5.4 関連研究
Bassら [9] は、World Wide Webのアーキテクチャに関する章を設けていますが、その説明はCERN/W3Cが開発したlibwww(クライアントおよびサーバーライブラリ)とJigsawソフトウェア内の実装アーキテクチャに限定されています。これらの実装は、Webのアーキテクチャ設計とその理論に精通した人々によって開発されたため、RESTの設計制約の多くを反映していますが、実際のWWWアーキテクチャは単一の実装に依存しません。現代のWebは、その標準インターフェースとプロトコルによって定義されており、それらのインターフェースとプロトコルが特定のソフトウェアでどのように実装されているかではありません。
RESTスタイルは、多くの既存の分散プロセスパラダイム [6, 50]、通信プロトコル、およびソフトウェア分野から引き出されています。RESTコンポーネントの相互作用は、階層化されたクライアント-サーバースタイルで構造化されていますが、汎用リソースインターフェースの追加制約により、仲介者による置換性と検査の機会が生まれます。リクエストとレスポンスはリモート呼び出しスタイルのように見えますが、RESTメッセージは実装識別子ではなく、概念的なリソースを対象としています。
Webアーキテクチャを分散ファイルシステム(例:WebNFS)または分散オブジェクトシステム [83] としてモデル化する試みがいくつか行われています。しかし、それらはさまざまなWebリソースタイプや実装戦略を「興味深くない」として除外していますが、実際にはそれらの存在がそのようなモデルの前提を無効にします。RESTは、リソースの実装を特定の事前定義モデルに制限しないため、各アプリケーションが自身のニーズに最適な実装を選択できるようにし、ユーザーに影響を与えることなく実装を置き換えることを可能にします。
リソースの表現を消費コンポーネントに送信する相互作用方法は、イベントベース統合(EBI)スタイルといくつかの類似点があります。主な違いは、EBIスタイルがプッシュベースであることです。状態を含むコンポーネント(RESTのオリジンサーバーに相当)は、状態が変化するたびにイベントを発行しますが、そのイベントに実際に興味を持っているか、またはそれを監視しているコンポーネントがあるかどうかは関係ありません。RESTスタイルでは、消費コンポーネントは通常、表現をプルします。単一のリソースを監視したい単一のクライアントとして見ると、これは効率が悪いですが、Webの規模を考えると、無制限のプッシュモデルは実現不可能です。
WebにおけるRESTスタイルの原則的な使用は、コンポーネント、コネクタ、および表現の明確な概念と密接に関連しており、C2アーキテクチャスタイル [128] と関連しています。C2スタイルは、基盤の独立性を実現するためにコネクタの構造化された使用に焦点を当てることで、分散型で動的なアプリケーションの開発をサポートします。C2アプリケーションは、状態変更とリクエストメッセージの非同期通知に依存します。他のイベントベースのスキームと同様に、C2は名目上プッシュベースですが、C2アーキテクチャはリクエストを受信したときにのみ通知を発行することで、RESTのプルスタイルで動作する可能性があります。しかし、C2スタイルには、汎用リソースインターフェース、保証されたステートレスな相互作用、キャッシュの内在的なサポートなど、RESTの仲介者に優しい制約が欠けています。
5.5 まとめ
この章では、分散型ハイパーメディアシステムのためのRepresentational State Transfer(REST)アーキテクチャスタイルを紹介しました。RESTは、全体として適用される一連のアーキテクチャ制約を提供し、コンポーネント間の相互作用のスケーラビリティ、インターフェースの汎用性、コンポーネントの独立したデプロイメント、および相互作用の遅延を減らし、セキュリティを強化し、レガシーシステムをカプセル化するための仲介コンポーネントを強調します。私は、RESTを導くソフトウェアエンジニアリングの原則と、それらの原則を維持するために選択された相互作用の制約について説明し、それらを他のアーキテクチャスタイルの制約と対比しました。
次の章では、RESTを現代のWebアーキテクチャの設計、仕様、およびデプロイメントに適用した経験と学びを通じて、RESTアーキテクチャの評価を提示します。この作業には、ハイパーテキスト転送プロトコル(HTTP/1.1)およびUniform Resource Identifiers(URI)の現在のインターネット標準トラック仕様の作成、およびlibwww-perlクライアントプロトコルライブラリとApache HTTPサーバーを通じたアーキテクチャの実装が含まれています。
第6章
経験と評価
1994年以降、RESTアーキテクチャスタイルは、モダンなWebのアーキテクチャ設計と開発をガイドするために使用されてきました。この章では、ハイパーテキスト転送プロトコル(HTTP)と統一リソース識別子(URI)という、Web上のすべてのコンポーネント間相互作用で使用される汎用インターフェースを定義する2つの仕様のインターネット標準の作成にRESTを応用した経験と学んだ教訓、およびこれらの技術をlibwww-perlクライアントライブラリ、Apache HTTPサーバープロジェクト、その他のプロトコル標準の実装として展開した経験について説明します。
6.1 ウェブの標準化
第4章で述べたように、RESTを開発する動機は、ウェブがどのように機能すべきかを示すアーキテクチャモデルを作成し、それをもとにウェブプロトコル標準のガイドとなるフレームワークを提供することでした。RESTは、望ましいウェブアーキテクチャを記述し、既存の問題を特定し、代替ソリューションを比較し、プロトコルの拡張がウェブの成功を支える核となる制約を侵害しないことを保証するために適用されてきました。この作業は、インターネット技術タスクフォース(IETF)とワールドワイドウェブコンソーシアム(W3C)がウェブのアーキテクチャ標準(HTTP、URI、HTML)を定義する取り組みの一環として行われました。 私がウェブ標準化プロセスに関わるようになったのは、1993年後半に、MOMspider [39]のクライアントコネクタインターフェースとして機能するlibwww-perlプロトコルライブラリを開発していた頃です。当時、ウェブのアーキテクチャは、一連のインフォーマルなハイパーテキストノート [14]、2つの初期の紹介論文 [12, 13]、ウェブの提案機能を表すドラフトハイパーテキスト仕様(一部はすでに実装されていました)、そして世界中のWWWプロジェクト参加者による非公式な議論が行われた公開のwww-talkメーリングリストのアーカイブによって説明されていました。各仕様は、ウェブの実装と比較して大幅に時代遅れになっており、その主な理由はMosaicグラフィカルブラウザの登場後の急速な進化でした [NCSA]。プロキシを許可するためにHTTPにいくつかの実験的な拡張が追加されていましたが、ほとんどの場合、プロトコルはユーザーエージェントとHTTPオリジンサーバーまたはレガシーシステムへのゲートウェイとの直接接続を前提としていました。アーキテクチャ内ではキャッシュ、プロキシ、またはスパイダーの存在が認識されておらず、それにもかかわらず実装は容易に利用可能で、無秩序に動作していました。プロトコルの次のバージョンに含めるため、多くの他の拡張が提案されていました。 同時に、業界内ではウェブインターフェースプロトコルのいくつかのバージョンを標準化する圧力が高まっていました。W3CはBerners-Lee [20]によって、ウェブアーキテクチャのシンクタンクとして機能し、ウェブ標準とリファレンス実装を記述するために必要な著者リソースを提供するために設立されましたが、標準化自体はインターネット技術タスクフォース [www.ietf.org] とそのURI、HTTP、HTMLに関する作業部会によって管理されていました。ウェブソフトウェア開発の経験があったため、私は最初に相対URLの仕様 [40] の著者に選ばれ、その後Henrik Frystyk NielsenとともにHTTP/1.0仕様 [19] の著者としてチームを組み、HTTP/1.1の主要なアーキテクチャ [42] となり、最終的にURL仕様の改訂を行いURI汎用構文の標準 [21] を形成しました。
RESTの最初の版は1994年10月から1995年8月の間に開発されました。主に、HTTP/1.0仕様と初期のHTTP/1.1提案を記述する際にウェブの概念を伝える手段として使用されました。その後、5年間にわたって反復的に改善され、ウェブプロトコル標準のさまざまな改訂と拡張に適用されました。RESTは当初「HTTPオブジェクトモデル」と呼ばれていましたが、この名前はHTTPサーバーの実装モデルと誤解されることが多々ありました。「Representational State Transfer」という名前は、うまく設計されたウェブアプリケーションがどのように振る舞うかをイメージさせることを意図しています。つまり、ウェブページのネットワーク(仮想状態機械)であり、ユーザーがリンク(状態遷移)を選択することでアプリケーションを進め、次のページ(アプリケーションの次の状態を表す)がユーザーに転送され、使用するためにレンダリングされるというものです。 RESTは、ウェブプロトコル標準のすべての可能な使用法を網羅することを意図していません。分散ハイパーメディアシステムのアプリケーションモデルに一致しないHTTPやURIの使用例もあります。しかし、重要なのは、RESTがそれらの要件をすべて網羅していることです。
分散ハイパーメディアシステムの側面は、Webの動作およびパフォーマンス要件において中心的なものと見なされており、モデル内での動作を最適化することで、展開されたWebアーキテクチャ内での最適な動作が実現されます。言い換えれば、RESTは一般的なケースに対して最適化されているため、Webアーキテクチャに適用される制約も一般的なケースに対して最適化されます。
6.2 RESTをURIに適用する
ユニフォームリソース識別子(URI)は、Webアーキテクチャの中で最もシンプルでありながら最も重要な要素です。URIは、WWWアドレス、ユニバーサルドキュメント識別子、ユニバーサルリソース識別子[15]、そして最終的にユニフォームリソースロケータ(URL)[17]と名前(URN)[124]の組み合わせとして知られてきました。名前は変わりましたが、URIの構文は1992年以来比較的変わっていません。しかし、Webアドレスの仕様は、私たちが_リソース_と呼ぶものの範囲とセマンティクスも定義しており、これは初期のWebアーキテクチャ以来変化しています。RESTは、URI標準[21]のためのリソースという用語を定義するために使用され、リソースをその表現を通じて操作するための汎用的なインターフェースの全体的なセマンティクスも定義しました。
6.2.1 リソースの再定義
初期のWebアーキテクチャでは、URIはドキュメント識別子として定義されていました。著者は、ネットワーク上のドキュメントの場所に基づいて識別子を定義するように指示されていました。Webプロトコルを使用してそのドキュメントを取得できるようにしました。しかし、この定義はいくつかの理由で不満足なものでした。まず、著者が転送されるコンテンツを識別していることを示唆しており、コンテンツが変更されるたびに識別子も変更されるべきであることを意味します。次に、ドキュメントではなくサービスに対応する多くのアドレスが存在します。著者は、そのサービスへのアクセスの特定の結果ではなく、そのサービス自体に読者を向けさせようとしている可能性があります。最後に、特定の期間においてドキュメントに対応しないアドレスが存在します。例えば、ドキュメントがまだ存在しない場合や、アドレスが情報を位置づけるのではなく、名前をつけるために使用されている場合です。 RESTにおける_リソース_の定義は、シンプルな前提に基づいています:識別子はできるだけ頻繁に変更されるべきではありません。Webはリンクサーバーではなく埋め込み識別子を使用するため、著者はハイパーメディア参照の意図するセマンティクスに近い識別子が必要です。これにより、参照は静的のままであるが、その参照にアクセスした結果は時間の経過とともに変化することができます。RESTは、リソースを著者が識別しようとしているセマンティクスとして定義し、参照が作成された時点でのそれらのセマンティクスに対応する値ではなく、これを実現します。そのため、著者は参照に対して選択した識別子が実際に意図したセマンティクスを識別することを確認する必要があります。
6.2.2 影の操作
リソースをURIがドキュメントではなく概念を識別するように定義すると、別の質問が残ります:ユーザーがハイパーテキストリンクを選択したときに有用な何かを得るために、概念にアクセス、操作、または転送するにはどうすればよいでしょうか?RESTは、操作されるものを識別されたリソースそのものではなく、その表現であると定義することでこの質問に答えます。オリジンサーバーは、リソース識別子から各リソースに対応する表現のセットへのマッピングを維持します。したがって、リソースはリソース識別子によって定義された汎用的なインターフェースを通じて表現を転送することによって操作されます。 RESTのリソース定義は、Webの中心的な要件から派生しています:複数の信頼ドメインにまたがる相互接続されたハイパーテキストの独立したオーサリング。インターフェース定義をインターフェース要件に一致させることで、プロトコルが曖昧に見えますが、それは操作されるインターフェースがインターフェースであり実装ではないからです。プロトコルはアプリケーションアクションの意図について具体的ですが、インターフェースの背後にあるメカニズムはその意図がリソースマッピングから表現への基礎となる実装にどのように影響するかを決定しなければなりません。
情報隠蔽は、RESTの均一なインターフェースを動機づける重要なソフトウェアエンジニアリング原則の1つです。クライアントは操作に制限されているため、
リソースの実装に直接アクセスするのではなく、表現を介してアクセスすることで、命名権限が望む形式で実装を構築することができ、その表現を使用するクライアントに影響を与えません。さらに、リソースにアクセスする際に複数の表現が存在する場合、コンテンツ選択アルゴリズムを使用して、そのクライアントの能力に最適な表現を動的に選択することができます。もちろん、欠点は、リソースのリモートオーサリングがファイルのリモートオーサリングほど簡単ではないことです。
6.2.3 リモートオーサリング
Webの統一インターフェースを介したリモートオーサリングの課題は、クライアントが取得できる表現と、サーバーがその表現のコンテンツを保存、生成、または取得するために使用するメカニズムの分離にあります。個々のサーバーは、その名前空間の一部をファイルシステムにマッピングし、それがディスク位置にマッピングできるinodeに相当するものにマッピングするかもしれませんが、これらの基盤となるメカニズムは、リソース自体を識別するのではなく、リソースを一連の表現に関連付ける手段を提供します。多くの異なるリソースが同じ表現にマッピングされる可能性があり、他のリソースはまったく表現がマッピングされていない可能性があります。
既存のリソースをオーサリングするためには、オーサーはまず特定のソースリソースURIを取得する必要があります。これは、ターゲットリソースのハンドラーの基盤となる表現にバインドするURIのセットです。リソースが常に単一のファイルにマッピングされるわけではありませんが、静的でないすべてのリソースは他のリソースから派生しており、派生ツリーをたどることで、リソースの表現を変更するために編集する必要があるすべてのソースリソースを最終的に見つけることができます。これらの同じ原則は、コンテンツネゴシエーション、スクリプト、サーブレット、管理された構成、バージョン管理など、派生した表現のどの形式にも適用されます。
リソースはストレージオブジェクトではありません。リソースは、サーバーがストレージオブジェクトを処理するために使用するメカニズムでもありません。リソースは概念的なマッピングです。サーバーは識別子(マッピングを識別する)を受け取り、それを現在のマッピング実装(通常はコレクション固有の深いツリートラバーサルやハッシュテーブルの組み合わせ)に適用して、現在責任を負うハンドラー実装を見つけ、ハンドラー実装はリクエスト内容に基づいて適切なアクションとレスポンスを選択します。これらの実装固有の問題はすべてWebインターフェースの背後に隠されています。その性質は、Webインターフェースを通じてのみアクセスできるクライアントによって想定することはできません。
たとえば、Webサイトのユーザーベースが成長し、XOSプラットフォームに基づく古いBrand Xサーバーを、FreeBSD上で動作する新しいApacheサーバーに置き換えることを決定した場合を考えてみましょう。ディスクストレージハードウェアが置き換えられます。オペレーティングシステムが置き換えられます。HTTPサーバーが置き換えられます。おそらく、すべてのコンテンツに対するレスポンスを生成する方法も置き換えられます。しかし、変更する必要がないのはWebインターフェースです。正しく設計されていれば、新しいサーバー上の名前空間は古いサーバーのものをミラーリングできるため、リソースの実装方法を知らないクライアントの観点からは、サイトの堅牢性が向上したこと以外は何も変わっていないように見えます。
6.2.4 URIにセマンティクスをバインドする
前述のように、リソースは多くの識別子を持つことができます。言い換えれば、サーバーにアクセスする際に同等のセマンティクスを持つ2つ以上の異なるURIが存在する可能性があります。また、サーバーにアクセスする際に同じメカニズムが使用される2つのURIが存在する可能性もありますが、それらのURIは同じ意味を持たないため、2つの異なるリソースを識別します。
セマンティクスは、リソース識別子を割り当て、それらのリソースに表現を投入する行為の副産物です。サーバーやクライアントがセマンティクスを直接操作することはありません。
ソフトウェアはURIの意味を知る必要はなく、理解する必要もありません。それらは単に、リソースの作成者(人間の命名権威)がURIによって識別されるセマンティクスに表現を関連付けることができる仲介役として機能します。言い換えれば、サーバー上にはリソースは存在せず、リソースによって定義された抽象インターフェースを介して答えを提供するメカニズムだけが存在します。奇妙に思えるかもしれませんが、これがWebが多くの異なる実装で機能する本質です。
すべてのエンジニアは、完成品を構成するコンポーネントの特性に基づいて物事を定義する性質を持っています。しかし、Webはそのようには機能しません。Webアーキテクチャは、アプリケーションアクション中の各コンポーネントの役割に基づいて、コンポーネント間の通信モデルに制約を課すことで構成されています。これにより、コンポーネントはリソース抽象化を超えて何かを推測することを防ぎ、抽象インターフェースの両側の実際のメカニズムを隠蔽します。
6.2.5 URIにおけるRESTのミスマッチ
ほとんどの現実世界のシステムと同様に、展開されたWebアーキテクチャのすべてのコンポーネントが、そのアーキテクチャ設計に存在するすべての制約に従っているわけではありません。RESTは、アーキテクチャの改善を定義する手段として、またアーキテクチャのミスマッチを識別する手段として使用されてきました。無知や見落としにより、アーキテクチャの制約に違反するソフトウェア実装が展開されると、ミスマッチが発生します。一般的にミスマッチを避けることはできませんが、それらが標準化される前に識別することは可能です。
URI設計はRESTの識別子のアーキテクチャ概念に合致していますが、構文だけでは命名権威がリソースモデルに従って自身のURIを定義することを強制するには不十分です。一つの形の悪用は、ハイパーメディア応答表現によって参照されるすべてのURI内に現在のユーザーを識別する情報を含めることです。このような埋め込まれたユーザーIDは、サーバー上でセッション状態を維持したり、ユーザーの行動をログに記録して追跡したり、複数のアクションにわたってユーザー設定を運ぶために使用されるかもしれません(例えば、Hyper-Gのゲートウェイ[84])。しかし、RESTの制約に違反することで、これらのシステムは共有キャッシュを無効にし、サーバーのスケーラビリティを低下させ、ユーザーがそれらの参照を他の人と共有したときに望ましくない効果をもたらします。
RESTのリソースインターフェースとの別の衝突は、ソフトウェアがWebを分散ファイルシステムとして扱おうとするときに発生します。ファイルシステムはその情報の実装を公開するため、複数のサイトにまたがってその情報を「ミラーリング」するツールが存在し、負荷分散やユーザーに近い場所にコンテンツを再配布する手段として機能します。しかし、ファイルには固定されたセマンティクス(名前付きのバイトシーケンス)があり、簡単に複製できるため、これが可能です。対照的に、Webサーバーのコンテンツをファイルとしてミラーリングしようとすると、リソースインターフェースが常にファイルシステムのセマンティクスと一致するわけではなく、データとメタデータの両方が表現のセマンティクスに含まれ、重要であるため失敗します。Webサーバーのコンテンツはリモートサイトで複製できますが、それはサーバーメカニズムと設定全体を複製するか、静的であることがわかっているリソースの表現のみを選択的に複製することによってのみ可能です(例えば、キャッシュネットワークはWebサイトと契約して、特定のリソース表現をインターネット全体の「エッジ」に複製し、遅延を減らし、オリジンサーバーからの負荷を分散します)。
6.3 RESTをHTTPに適用する
ハイパーテキスト転送プロトコル(HTTP)は、ウェブコンポーネント間の主要なアプリケーションレベルプロトコルとして、またリソース表現の転送のために特別に設計された唯一のプロトコルとして、ウェブアーキテクチャにおいて特別な役割を果たしています。URIとは異なり、現代のウェブアーキテクチャをサポートするためにはHTTPに多くの変更が必要でした。HTTPの実装開発者は、提案された拡張機能の採用に慎重であり、そのため拡張機能は展開される前に実証され、標準審査を受ける必要がありました。RESTは、既存のHTTP実装の問題を特定し、そのプロトコルの相互運用可能なサブセットをHTTP/1.0として指定し[19]、HTTP/1.1の提案された拡張を分析し[42]、HTTP/1.1の展開を促進するための理論的根拠を提供するために使用されました。
RESTによって特定されたHTTPの主な問題領域には、新しいプロトコルバージョンの展開計画、メッセージ解析をHTTPのセマンティクスと基盤となるトランスポート層(TCP)から分離すること、信頼できる応答と信頼できない応答を区別すること、キャッシュのきめ細かい制御、および自己記述的でないプロトコルのさまざまな側面が含まれていました。RESTはまた、HTTPに基づくウェブアプリケーションのパフォーマンスをモデル化し、持続的接続やコンテンツネゴシエーションなどの拡張機能の影響を予測するためにも使用されています。最後に、RESTは、標準化されたHTTP拡張の範囲をアーキテクチャモデルに適合するものに限定し、HTTPを誤用するアプリケーションが標準に同等に影響を与えることを防ぐために使用されています。
6.3.1 拡張性
RESTの主要な目標の1つは、既に展開されているアーキテクチャ内での変更を段階的かつ断片的に展開することをサポートすることです。HTTPは、バージョン管理の要件とプロトコルの構文要素を拡張するためのルールを導入することで、この目標をサポートするように変更されました。
6.3.1.1 プロトコルのバージョン管理
HTTPは、主要バージョン番号とマイナーバージョン番号で区別されるプロトコルファミリーであり、主に「http」URL名前空間に基づくサービスと直接通信する際に期待されるプロトコルに対応するため、この名前が付けられています。コネクタは、各メッセージに含まれるHTTPバージョンプロトコル要素に課せられた制約に従わなければなりません[90]。
メッセージのHTTPバージョンは、送信者のプロトコル能力と送信されるメッセージの大まかな互換性(主要バージョン番号)を表します。これにより、クライアントは通常のHTTP/1.1リクエストを行う際に、HTTP/1.0の機能サブセットを使用することができ、同時に受信者に対して完全なHTTP/1.1通信をサポートできることを示すことができます。言い換えると、これはHTTPスケールでのプロトコルネゴシエーションの暫定的な形式を提供します。リクエスト/レスポンスチェーン上の各接続は、そのチェーンの一部である一部のクライアントまたはサーバーの制限にもかかわらず、最適なプロトコルレベルで動作することができます。
プロトコルの意図は、サーバーが常にクライアントのリクエストメッセージと同じ主要バージョン内で理解する最高のマイナーバージョンのプロトコルで応答するべきであるということです。制約は、サーバーがそのような古いバージョンのクライアントに送信することが禁止されている高レベルのプロトコルのオプション機能を使用できないということです。すべてのマイナーバージョンと一緒に使用できない必須機能はありません。なぜなら、それは互換性のない変更であり、したがって主要バージョンの変更を必要とするからです。マイナーバージョン番号の変更に依存できるHTTPの唯一の機能は、通信中の直接の隣接者が解釈する機能です。なぜなら、HTTPは中間コンポーネントのリクエスト/レスポンスチェーン全体が同じバージョンを話すことを要求しないからです。
これらのルールは、複数のプロトコル改訂の展開を支援するために存在し、…
HTTPの設計者がプロトコルのデプロイメントが設計の重要な側面であることを忘れないようにします。彼らは、プロトコルの互換性のある変更と互換性のない変更を簡単に区別できるようにすることでこれを実現しています。互換性のある変更はデプロイが容易で、その違いをプロトコルストリーム内で伝えることができます。互換性のない変更はデプロイが難しく、プロトコルストリームを開始する前にプロトコルの受け入れを何らかの形で決定する必要があります。
6.3.1.2 拡張可能なプロトコル要素
HTTPには、それぞれ異なる制約を持ついくつかの独立した名前空間が含まれていますが、すべての名前空間は無制限に拡張可能であるという要件を共有しています。一部の名前空間は別のインターネット標準によって管理され、複数のプロトコルで共有されています(例:URIスキーム[21]、メディアタイプ[48]、MIMEヘッダーフィールド名[47]、文字セット値、言語タグ)。一方、他の名前空間はHTTPによって管理されており、メソッド名、レスポンスステータスコード、非MIMEヘッダーフィールド名、標準HTTPヘッダーフィールド内の値などが含まれます。初期のHTTPでは、これらの名前空間内の変更をどのようにデプロイするかについて一貫したルールを定義していなかったため、これは仕様策定で最初に取り組まれた問題の1つでした。
HTTPリクエストのセマンティクスはリクエストメソッド名によって示されます。メソッドの拡張は、クライアント、サーバー、およびそれらの間にある可能性のある仲介者が標準化可能なセマンティクスのセットを共有できる場合に許可されます。残念ながら、初期のHTTP拡張、特にHEADメソッドは、HTTPレスポンスメッセージの解析をリクエストメソッドのセマンティクスを知ることに依存させました。これにより、デプロイの矛盾が生じました:受信者がメソッドのセマンティクスを知る必要がある場合、新しいメソッドをデプロイする前にすべての仲介者を更新する必要があります。
このデプロイ問題は、HTTPメッセージの解析と転送のルールを新しいHTTPプロトコル要素に関連するセマンティクスから分離することで修正されました。例えば、HEADはContent-Lengthヘッダーフィールドがメッセージ本文の長さ以外の意味を持つ唯一のメソッドであり、新しいメソッドはメッセージ長の計算を変更できません。GETとHEADは、条件付きリクエストヘッダーフィールドがキャッシュの更新のセマンティクスを持つ唯一のメソッドであり、他のすべてのメソッドでは事前条件の意味を持ちます。
同様に、HTTPは新しいレスポンスステータスコードを解釈するための一般的なルールを必要としていました。これにより、古いクライアントに重大な損害を与えることなく新しいレスポンスをデプロイできるようになります。したがって、各ステータスコードがその3桁の10進数の最初の桁によって示されるクラスに属するというルールを拡張しました:100-199はメッセージが暫定的な情報レスポンスを含むことを示し、200-299はリクエストが成功したことを示し、300-399はリクエストが別のリソースにリダイレクトされる必要があることを示し、400-499はクライアントが繰り返すべきでないエラーを起こしたことを示し、500-599はサーバーがエラーに遭遇したが、クライアントが後で(または他のサーバー経由で)より良いレスポンスを得られる可能性があることを示します。受信者が特定のメッセージ内のステータスコードの具体的なセマンティクスを理解できない場合、そのクラス内のx00コードと同じように扱わなければなりません。メソッド名のルールと同様に、この拡張性ルールは現在のアーキテクチャに将来の変更を予期する要件を課します。したがって、既存のアーキテクチャに変更をデプロイする際に、コンポーネントの反応に対する懸念を軽減できます。
6.3.1.3 アップグレード
HTTP/1.1でのUpgradeヘッダーフィールドの追加は、クライアントが古いプロトコルストリームで通信しながら、より良いプロトコルを受け入れる意思を示すことを可能にすることで、互換性のない変更のデプロイの難しさを軽減します。Upgradeは、HTTP/1.xを他の将来のプロトコルで選択的に置き換えることをサポートするために特に追加されました。
一部のタスクに対してより効率的である可能性があります。したがって、HTTPは内部の拡張性をサポートするだけでなく、アクティブな接続中に自身を完全に置き換えることもサポートしています。サーバーが改善されたプロトコルをサポートし、切り替えを希望する場合、単に101ステータスで応答し、そのアップグレードされたプロトコルでリクエストを受信したかのように続行します。
6.3.2 自己記述型メッセージ
RESTは、コンポーネント間のメッセージを自己記述型にすることを制約し、相互作用の中間処理をサポートします。しかし、初期のHTTPには自己記述型でない側面がありました。これには、リクエスト内のホスト識別の欠如、メッセージ制御データと表現メタデータの文法的な区別の欠如、即時の接続ピアのみを対象とした制御データとすべての受信者を対象としたメタデータの区別の欠如、必須拡張のサポートの欠如、および階層化されたエンコーディングを持つ表現を記述するためのメタデータの必要性が含まれます。
6.3.2.1 ホスト
初期のHTTPデザインにおける最悪の過ちの一つは、リクエストメッセージの対象となる完全なURIを送信しないという決定でした。代わりに、接続の設定に使用されなかった部分のみを送信しました。この仮定は、サーバーが接続のIPアドレスとTCPポートに基づいて自身の命名権限を知っているというものでした。しかし、これは単一のサーバー上に複数の命名権限が存在する可能性を予期しておらず、Webが指数関数的に成長し、新しいドメイン名(http URL名前空間内の命名権限の基礎)が新しいIPアドレスの可用性をはるかに超えるにつれて、重大な問題となりました。 HTTP/1.0とHTTP/1.1の両方に対して定義され展開された解決策は、リクエストメッセージのHostヘッダーフィールド内に対象URLのホスト情報を含めることでした。この機能の展開は非常に重要であると考えられ、HTTP/1.1仕様では、Hostフィールドを含まないHTTP/1.1リクエストをサーバーが拒否するよう要求しています。その結果、現在では単一のIPアドレス上で数万の名前ベースの仮想ホストウェブサイトを実行する多くの大規模ISPサーバーが存在します。
6.3.2.2 階層化エンコーディング
HTTPは、表現メタデータを記述するための構文をMultipurpose Internet Mail Extensions (MIME) [47]から継承しました。MIMEは階層化されたメディアタイプを定義せず、代わりにContent-Typeフィールド値内に外側のメディアタイプのラベルのみを含めることを好みます。しかし、これにより、レイヤーをデコードせずにエンコードされたメッセージの性質を判断することができなくなります。初期のHTTP拡張では、この欠点を回避するために、外側のエンコーディングをContent-Encodingフィールド内に別々にリストし、最も内側のメディアタイプのラベルをContent-Typeに配置しました。これは、フィールド名を変更せずにContent-Typeのセマンティクスを変更したため、古いユーザーエージェントが拡張機能に遭遇したときに混乱を引き起こすという、設計上の誤りでした。より良い解決策は、Content-Typeを外側のメディアタイプとして扱い続け、新しいフィールドを使用してそのタイプ内のネストされたタイプを記述することでした。残念ながら、最初の拡張はその欠点が認識される前に展開されました。 RESTは、ネットワーク上での転送性を向上させるためにコネクタによってメッセージに適用される別のレイヤーのエンコーディングの必要性を認識しました。この新しいレイヤーは、MIME内の類似の概念を参照してtransfer-encodingと呼ばれ、表現が本質的にエンコードされていることを意味せずに、メッセージを転送用にエンコードすることを可能にします。転送エージェントは、何らかの理由で転送エンコーディングを追加または削除することができ、それによって表現のセマンティクスを変更しません。
6.3.2.3 セマンティック独立性
上記のように、HTTPメッセージの解析はそのセマンティクスから分離されています。メッセージの解析、つまりヘッダーフィールドを見つけてまとめることは、ヘッダーフィールドの内容を解析するプロセスとは完全に分離されています。このように、
インターミディアリはHTTPメッセージを迅速に処理して転送することができ、拡張機能は既存のパーサーを壊すことなく展開できます。
6.3.2.4 トランスポート非依存性
HTTP/1.0を含む初期のHTTPは、基盤となるトランスポートプロトコルを使用して、レスポンスメッセージの終了を通知していました。サーバーはTCP接続を閉じることで、レスポンスメッセージの終了を示していました。残念ながら、これによりプロトコルに重大な欠陥が生じました。クライアントは、完全なレスポンスと、何らかのネットワークエラーによって切り詰められたレスポンスとを区別する手段を持っていなかったのです。これを解決するために、HTTP/1.0ではContent-Lengthヘッダーフィールドが再定義され、メッセージボディの長さが事前にわかっている場合はそのバイト数を示すようになりました。さらに、HTTP/1.1では「チャンク」転送エンコーディングが導入されました。
チャンクエンコーディングでは、生成開始時(ヘッダーフィールドが送信される時点)にサイズが不明な表現でも、送信前に個別にサイズを設定できる一連のチャンクによって境界を区切ることができます。また、メッセージの末尾にトレーラーとしてメタデータを送信することも可能で、メッセージ生成中にオリジンでオプションのメタデータを作成でき、レスポンスの遅延を増やすことなく実現できます。
6.3.2.5 サイズ制限
アプリケーション層プロトコルの柔軟性に対する頻繁な障壁は、プロトコルパラメーターのサイズ制限を過度に指定する傾向です。プロトコルの実装には常にいくつかの実用的な制限(例:利用可能なメモリ)が存在しますが、プロトコル内でこれらの制限を指定してしまうと、すべてのアプリケーションが同じ制限に縛られてしまいます。その結果、多くの場合、オリジナルの作成者が想定した範囲を超えて拡張できない最低限のプロトコルが生まれてしまいます。
HTTPプロトコルでは、URIの長さ、ヘッダーフィールドの長さ、表現の長さ、または項目リストで構成されるフィールド値の長さに制限はありません。古いWebクライアントには、255文字を超えるURIでよく知られた問題がありますが、HTTP仕様でその問題を指摘するだけで十分であり、すべてのサーバーにその制限を課す必要はありません。このようにプロトコルの最大値を設定しない理由は、制御された環境(イントラネットなど)内のアプリケーションが、古いコンポーネントを置き換えることでこれらの制限を回避できるからです。
人工的な制限を設ける必要はありませんでしたが、HTTP/1.1では、特定のプロトコル要素がサーバーにとって長すぎて処理できない場合を示すために、適切な一連のレスポンスステータスコードを定義する必要がありました。このようなレスポンスコードは、Request-URIが長すぎる、ヘッダーフィールドが長すぎる、ボディが長すぎるという状況に対して追加されました。残念ながら、クライアントがサーバーに対してリソース制限があることを示す方法はなく、PDAなどのリソース制約のあるデバイスが、デバイス固有のインターミディアリによる通信調整なしにHTTPを使用しようとすると問題が発生します。
6.3.2.6 キャッシュ制御
RESTは、効率的で低遅延の動作と、意味的に透明なキャッシュ動作のバランスを取ろうとするため、HTTPがアプリケーションにキャッシュ要件を決定させるようにすることが重要であり、プロトコル自体にハードコードすることは避けなければなりません。プロトコルが最も重視すべきは、転送されるデータを完全かつ正確に記述することで、アプリケーションが実際とは異なるものを手にしていると誤解しないようにすることです。HTTP/1.1では、Cache-Control、Age、Etag、およびVaryヘッダーフィールドを追加することでこれを実現しています。
6.3.2.7 コンテンツネゴシエーション
すべてのリソースは、リクエスト(メソッド、識別子、リクエストヘッダーフィールド、および場合によっては表現で構成される)をレスポンス(ステータスコード、レスポンスヘッダーフィールド、および場合によっては表現で構成される)にマッピングします。HTTPリクエストがサーバー上の複数の表現にマッピングされる場合、サーバーはクライアントとコンテンツネゴシエーションを行うことがあります。
クライアントのニーズに最適なものを決定するためには、これは本当に「コンテンツ選択」プロセスであり、交渉ではありません。 コンテンツネゴシエーションの実装はいくつか存在しましたが、HTTP/1.0の仕様には含まれませんでした。なぜなら、仕様が公開された時点で相互運用可能な実装のサブセットが存在しなかったからです。これは、NCSA Mosaicの貧弱な実装が原因の一部でした。NCSA Mosaicは、リソースのネゴシエーション可能性に関係なく、すべてのリクエストでヘッダーフィールドに1KBの設定情報を送信していました [125]。すべてのURIのうち、コンテンツがネゴシエーション可能なものは0.01%未満であるため、結果としてリクエストのレイテンシが大幅に増加し、利益がほとんど得られませんでした。これにより、後のブラウザはHTTP/1.0のネゴシエーション機能を無視するようになりました。
事前(サーバー主導)ネゴシエーションは、サーバーが特定のリクエストメソッド識別子ステータスコードの組み合わせに対して、リクエストヘッダーフィールドの値または通常のリクエストパラメータ以外の何かに基づいてレスポンスの表現を変える場合に発生します。これが発生した場合、クライアントに通知する必要があります。これにより、キャッシュは特定のキャッシュされたレスポンスを将来のリクエストに対して意味的に透過的に使用できるかどうかを知ることができ、またユーザーエージェントはレスポンスに影響を与えることを知った後に、通常送信するよりも詳細な設定を提供することができます。HTTP/1.1では、この目的のために Va r y ヘッダーフィールドが導入されました。Varyは単に、レスポンスが変わる可能性のあるリクエストヘッダーフィールドの次元をリストします。
事前ネゴシエーションでは、ユーザーエージェントはサーバーに対して受け入れることができるものを伝えます。サーバーは、ユーザーエージェントがその能力として主張するものに最も一致する表現を選択する必要があります。ただし、これは解決が難しい問題です。なぜなら、UAが受け入れるものに関する情報だけでなく、各機能を受け入れる程度や、ユーザーがその表現をどのように使うつもりかに関する情報も必要となるためです。たとえば、画面上で画像を表示したいユーザーは、シンプルなビットマップ表現を好むかもしれませんが、同じブラウザを使用している同じユーザーが、プリンターに送信するつもりであれば、PostScript表現を好むかもしれません。また、ユーザーが自分のコンテンツ設定に従ってブラウザを正しく設定しているかどうかにも依存します。要するに、サーバーが事前ネゴシエーションを効果的に利用できることはめったにありませんが、これは初期のHTTPで定義された唯一の自動コンテンツ選択の形式でした。
HTTP/1.1では、反応的(エージェント主導)ネゴシエーションの概念が追加されました。この場合、ユーザーエージェントがネゴシエーション可能なリソースをリクエストすると、サーバーは利用可能な表現のリストを返します。ユーザーエージェントは、その能力と目的に応じて、最適なものを選択できます。利用可能な表現に関する情報は、別の表現(例:300レスポンス)として、レスポンスデータ内(例:条件付きHTML)として、または「最も可能性が高い」レスポンスの補足として提供される場合があります。後者はWebにとって最適です。なぜなら、追加の相互作用は、ユーザーエージェントが他のバリアントの方が良いと判断した場合にのみ必要となるためです。反応的ネゴシエーションは、通常のブラウザモデルの自動反映にすぎないため、RESTのすべてのパフォーマンス上の利点を最大限に活用できます。
事前ネゴシエーションと反応的ネゴシエーションの両方とも、表現の次元の実際の特性を伝える難しさ(例:ブラウザがHTMLテーブルをサポートしているがINSERT要素をサポートしていないことを伝える方法)に苦しんでいます。しかし、反応的ネゴシエーションには、すべてのリクエストで設定を送信する必要がないこと、代替案に直面したときに決定を下すためのより多くのコンテキスト情報があること、キャッシュを妨げないことという明確な利点があります。
第三のネゴシエーション形式である透過的ネゴシエーション [64] は、他のエージェントに代わってより良い選択を行うためのエージェントとして、中間キャッシュが行動することを許可するものです。
表現を取得するためのリクエストの表現と開始。リクエストは内部で別のキャッシュヒットによって解決される可能性があり、そのため追加のネットワークリクエストが行われない場合があります。しかし、その際にサーバー主導のネゴシエーションを行っているため、他のアウトバウンドキャッシュが混乱しないように適切なVary情報を追加する必要があります。
6.3.3 パフォーマンス
HTTP/1.1は、コンポーネント間の通信セマンティクスの改善に焦点を当てましたが、HTTP/1.0との構文互換性の要件によって制限されながらも、ユーザーが感じるパフォーマンスの改善もいくつか行われました。
6.3.3.1 持続的接続
初期のHTTPの1リクエスト/1レスポンスごとの接続動作は、実装を単純にする一方で、各インタラクションのセットアップコストのオーバーヘッドやTCPのスロースタート輻輳制御アルゴリズムの性質により、基盤となるTCPトランスポートの効率的な使用を妨げました[63, 125]。その結果、単一の接続内で複数のリクエストとレスポンスを組み合わせるためのいくつかの拡張が提案されました。
最初の提案は、単一のメッセージ内に複数のリクエストをカプセル化し(MGET、MHEADなど)、レスポンスをMIMEマルチパートとして返す新しいメソッドのセットを定義することでした。これは、RESTの制約のいくつかに違反するため却下されました。まず、クライアントは最初のリクエストをネットワークに書き込む前に、パッケージ化したいすべてのリクエストを知る必要がありました。なぜなら、リクエストボディは初期リクエストヘッダフィールドに設定されたcontent-lengthフィールドによって長さが区切られる必要があるからです。第二に、仲介者は各メッセージを抽出して、どのメッセージをローカルで満たすことができるかを判断する必要がありました。最後に、これは事実上リクエストメソッドの数を倍増させ、特定のメソッドへのアクセスを選択的に拒否するメカニズムを複雑にします。
代わりに、単一の接続上で複数のHTTPメッセージを送信するために長さ区切りのメッセージを使用する持続的接続の形式を採用しました[100]。HTTP/1.0では、これはConnectionヘッダフィールド内の「keep-alive」ディレクティブを使用して行われました。残念ながら、これは一般的には機能しませんでした。なぜなら、ヘッダフィールドはkeep-aliveを理解しない他の仲介者に転送される可能性があり、デッドロック状態を引き起こすからです。HTTP/1.1は最終的に持続的接続をデフォルトとし、その存在をHTTPバージョン値で示し、デフォルトを逆転させるためにのみ「close」接続ディレクティブを使用することにしました。
持続的接続は、HTTPメッセージが自己記述的で基盤となるトランスポートプロトコルから独立するように再定義された後に初めて可能になったことに注意することが重要です。
6.3.3.2 ライトスルーキャッシュ
HTTPはライトバックキャッシュをサポートしていません。HTTPキャッシュは、そこに書き込まれたものがそのリソースの後続のリクエストで取得できるものと同じであると仮定することはできず、したがってPUTリクエストボディをキャッシュして後でGETレスポンスに再利用することはできません。このルールには2つの理由があります:1)メタデータが背後で生成される可能性があること、2)後続のGETリクエストに対するアクセス制御をPUTリクエストから決定できないことです。しかし、Webを使用した書き込みアクションは非常に稀であるため、ライトバックキャッシュの欠如はパフォーマンスに重大な影響を与えません。
6.3.4 HTTPにおけるRESTのミスマッチ
HTTP内にはいくつかのアーキテクチャ上のミスマッチが存在します。その一部は、標準プロセスの外部で展開されたサードパーティの拡張によるものであり、他は展開されたHTTP/1.0コンポーネントとの互換性を維持する必要性によるものです。
6.3.4.1 非権威あるレスポンスの識別
HTTPにまだ存在する弱点の1つは、現在のリクエストに応じてオリジンサーバーによって生成された権威あるレスポンスと、オリジンサーバーにアクセスせずに仲介者やキャッシュから取得された非権威あるレスポンスを区別するための一貫したメカニズムがないことです。この区別は、
6.3.4.2 クッキー
プロトコルに対して不適切な拡張が行われ、ジェネリックインターフェースの望ましい特性と矛盾する機能をサポートする例として、HTTPクッキー[73]の形でのサイト全体の状態情報の導入が挙げられます。クッキーの相互作用は、RESTのアプリケーション状態のモデルに適合せず、典型的なブラウザアプリケーションでの混乱を引き起こすことがよくあります。
HTTPクッキーは、オリジンサーバーがユーザーエージェントに割り当てることができる不透明なデータで、Set-Cookie応答ヘッダーフィールドに含めることによって提供されます。その意図は、ユーザーエージェントがそのサーバーに対する将来のすべてのリクエストに同じクッキーを含めるべきであり、それが置き換えられるか期限切れになるまで続けることです。このようなクッキーには、通常、ユーザー固有の設定選択の配列や、将来のリクエストでサーバーのデータベースと照合するためのトークンが含まれています。問題は、クッキーが特定のアプリケーション状態(現在レンダリングされている表現のセット)ではなく、通常はサイト全体を含む特定のリソース識別子のセットに対する将来のリクエストに添付されるように定義されていることです。ブラウザの履歴機能(「戻る」ボタン)を使用してクッキーに反映されたビュー以前のビューに戻った場合、ブラウザのアプリケーション状態はクッキー内に保存された状態と一致しなくなります。そのため、同じサーバーに送信される次のリクエストには、現在のアプリケーションコンテキストを誤って表現するクッキーが含まれることになり、双方で混乱を引き起こします。
クッキーはまた、データのセマンティクスを十分に識別せずにデータを渡すことを許可するため、セキュリティとプライバシーの両方にとって懸念となります。クッキーとReferer [原文ママ]ヘッダーフィールドの組み合わせにより、ユーザーがサイト間をブラウズする際に追跡することが可能になります。
その結果、Web上のクッキーベースのアプリケーションは決して信頼性のあるものにはなりません。同じ機能は、匿名認証と真のクライアントサイドの状態によって実現されるべきでした。設定を伴う状態メカニズムは、クッキーではなく、コンテキスト設定URIを適切に使用することでより効率的に実装できます。ここで「適切」とは、ユーザーIDの埋め込みによる無制限のURIではなく、状態ごとに1つのURIを使用することを意味します。同様に、サーバーサイドのデータベース内でユーザー固有の「ショッピングバスケット」を識別するためにクッキーを使用する代わりに、ハイパーメディアデータ形式内でショッピングアイテムのセマンティクスを定義し、ユーザーエージェントがそれらのアイテムを選択して独自のクライアントサイドのショッピングバスケットに保存し、クライアントが購入の準備ができたときにチェックアウトに使用するURIを提供する方が効率的です。
6.3.4.3 必須拡張
HTTPヘッダーフィールド名は、情報が必要な場合にのみ、自由に拡張できます。
6.3.4.4 メタデータの混合
HTTPは、ネットワーク接続を介した汎用的なコネクタインターフェースを拡張するように設計されています。そのため、制御データ、メタデータ、表現といったパラメータの区分を含む、そのインターフェースの特性に合わせることを意図しています。しかし、HTTP/1.xプロトコルファミリーの最も重要な制限の2つは、表現メタデータとメッセージ制御情報(両方ともヘッダーフィールドとして送信される)を構文的に区別できないことと、メッセージの整合性チェックのためにメタデータを効果的に階層化できないことです。RESTは、標準化プロセスの早い段階でこれらをプロトコルの制限として認識し、持続的接続やダイジェスト認証などの他の機能の展開に問題が生じると予見していました。そのため、中間者が転送するのに安全でない接続ごとの制御データを識別するためのConnectionヘッダーフィールドの追加や、ヘッダーフィールドのダイジェストを正規化するアルゴリズム[46]などの回避策が開発されました。
6.3.4.5 MIME構文
HTTPは、MIME [47]からメッセージ構文を継承しており、他のインターネットプロトコルとの共通性を維持し、メッセージ内のメディアタイプを記述するための標準化されたフィールドを再利用するためです。残念ながら、MIMEとHTTPは非常に異なる目的を持っており、その構文はMIMEの目的にのみ合わせて設計されています。MIMEでは、ユーザーエージェントが一連の情報を送信し、それを一貫した全体として扱い、直接やり取りしない未知の受信者に送信します。MIMEは、インターネットメールを介して複数のメッセージを送信するよりも効率的であるため、エージェントが1つのメッセージですべての情報を送信することを想定しています。したがって、MIME構文は、郵便業者がパッケージを追加の紙で包むのと同じように、メッセージをパートまたはマルチパート内にパッケージ化するように構築されています。HTTPでは、安全なカプセル化やパッケージアーカイブ以外で、単一のメッセージ内に異なるオブジェクトをパッケージ化することは意味がありません。なぜなら、キャッシュされていないドキュメントに対して別々のリクエストを行う方が効率的だからです。したがって、HTTPアプリケーションは、HTMLのようなメディアタイプを「パッケージ」への参照のコンテナとして使用します。ユーザーエージェントは、パッケージのどの部分を別々のリクエストとして取得するかを選択できます。HTTPが、最初のパートの後に非URIリソースのみを含むマルチパートパッケージを使用することも可能ですが、それに対する需要はあまりありませんでした。MIME構文の問題は、転送がロスがあることを前提にしており、改行やコンテンツの長さなどを意図的に破壊することです。そのため、構文は冗長で、ロスがない転送を基にしていないシステムにとっては非効率的であり、HTTPには不適切です。HTTP/1.1には互換性のないプロトコルの展開をサポートする能力があるため、次の主要バージョンのHTTPではMIME構文を保持する必要はありませんが、表現メタデータのための多くの標準化されたプロトコル要素は引き続き使用されるでしょう。
6.3.5 リクエストに対するレスポンスの対応づけ
HTTPメッセージは、どのレスポンスがどのリクエストに属するかを説明する際に自己記述的ではありません。初期のHTTPは、1つのリクエストと1つのレスポンスに基づいていました。
接続が1つしかないというシンプルな仕組みであったため、レスポンスをそれを引き起こしたリクエストに紐付けるためのメッセージ制御データは必要ないと考えられていました。そのため、リクエストの順序がレスポンスの順序を決定し、HTTPはマッチングを決定するためにトランスポート接続に依存しています。
HTTP/1.1は、トランスポートプロトコルから独立していると定義されていますが、通信が同期型トランスポート上で行われることを前提としています。リクエスト識別子を追加することで、非同期型トランスポート(例えば電子メール)でも動作するように簡単に拡張することができます。このような拡張は、ブロードキャストやマルチキャストの状況下で、レスポンスがリクエストとは異なるチャネルで受信される可能性があるエージェントにとって有用です。また、多くのリクエストが保留されている状況では、サーバーがレスポンスの転送順序を選択できるようになり、より小さなまたは重要なレスポンスを最初に送信することが可能になります。
6.4 技術移転
RESTはWeb標準の作成に最も直接的な影響を与えたが、その成果として商業グレードの実装が展開され、アーキテクチャ設計モデルとしての有用性が証明された。
6.4.1 libwww-perlの展開経験
私がWeb標準の定義に関わるようになったのは、メンテナンスロボットMOMspider [39]とその関連プロトコルライブラリであるlibwww-perlの開発から始まった。CERNのTim Berners-LeeとWWWプロジェクトが開発したオリジナルのlibwwwをモデルにしたlibwww-perlは、Perl言語で書かれたクライアントアプリケーション向けに、Webリクエストを作成し、Webレスポンスを解釈するための統一インターフェースを提供した [134]。これはオリジナルのCERNプロジェクトから独立して開発された初めてのWebプロトコルライブラリであり、古いコードベースよりも現代的なWebインターフェースの解釈を反映していた。このインターフェースがRESTの設計の基盤となった。
libwww-perlは単一のリクエストインターフェースを提供し、Perlの自己評価コード機能を使用して、要求されたURIのスキームに基づいて適切なトランスポートプロトコルパッケージを動的にロードした。例えば、URL <http://www.ebuilt.com/> に対して「GET」リクエストを行うよう要求されると、libwww-perlはURLからスキーム(「http」)を抽出し、すべてのタイプのリソース(HTTP、FTP、WAIS、ローカルファイルなど)に共通のインターフェースを使用して _wwwhttp’request() を呼び出した。この汎用インターフェースを実現するために、ライブラリはすべての呼び出しをHTTPプロキシとほぼ同じ方法で扱った。Perlのデータ構造を使用して、リソースのタイプにかかわらず、HTTPリクエストと同じセマンティクスを持つインターフェースを提供した。
libwww-perlは汎用インターフェースの利点を実証した。最初のリリースから1年以内に、600人以上の独立したソフトウェア開発者がコマンドラインのダウンロードスクリプトから本格的なブラウザまで、さまざまなクライアントツールにこのライブラリを使用していた。現在では、ほとんどのWebシステム管理ツールの基盤となっている。
6.4.2 Apacheの展開経験
HTTPの仕様策定が完全な仕様書の形をとり始めたことで、提案された標準プロトコルを効果的に実証し、価値のある拡張機能のテストベッドとしても機能するサーバーソフトウェアが必要になった。当時、最も人気のあるHTTPサーバー(httpd)は、イリノイ大学アーバナシャンペーン校の国立スーパーコンピューティング応用センター(NCSA)のRob McCoolが開発したパブリックドメインのソフトウェアだった。しかし、1994年半ばにRobがNCSAを離れた後、開発は停滞し、多くのWeb管理者が独自の拡張機能やバグ修正を開発し、共通の配布が必要とされていた。私たちのグループは、オリジナルのソースに対する変更を「パッチ」として調整する目的でメーリングリストを作成した。その過程で、Apache HTTP Server Project [89]が生まれた。
Apacheプロジェクトは、堅牢で商業グレードのフル機能オープンソースHTTPサーバーの実装を作成するための共同ソフトウェア開発プロジェクトである。このプロジェクトは世界中のボランティアグループが共同で管理し、インターネットとWebを使用してコミュニケーションを取り、計画を立て、サーバーとその関連ドキュメントを開発している。これらのボランティアはApache Groupと呼ばれる。その後、グループは非営利のApache Software Foundationを設立し、Apacheオープンソースプロジェクトの継続的な開発を支援するための法的および財政的な傘組織として活動している。
Apacheは、インターネットサービスの多様な要求に対する
Apache開発者たちの「HTTPを正しく実装する方法」という視点を標準化フォーラムで擁護する立場として、この章で説明されている多くの教訓は、Apacheプロジェクト内でHTTPのさまざまな実装を作成およびテストし、プロトコルの理論をApache Groupの批判的なレビューにさらすことで得られました。
Apache httpdは、最も成功したソフトウェアプロジェクトの1つであり、重要な商業競争が存在する市場を支配した最初のオープンソースソフトウェア製品の1つとして広く認識されています。2000年7月のNetcraftによる公開インターネットウェブサイトの調査では、Apacheソフトウェアを基盤とする2000万以上のサイトが確認され、調査対象の全サイトの65%以上を占めていました [http://www.netcraft.com/survey/]。ApacheはHTTP/1.1プロトコルをサポートした最初の主要なサーバーであり、すべてのクライアントソフトウェアがテストされる際のリファレンス実装と一般的に考えられています。Apache Groupは、Webアーキテクチャの標準に対する我々の影響を認められ、1999年のACMソフトウェアシステム賞を受賞しました。
6.4.3 URIおよびHTTP/1.1準拠ソフトウェアの展開
Apacheに加えて、商用およびオープンソースの多くのプロジェクトが、現代のWebアーキテクチャのプロトコルに基づくソフトウェア製品を採用し、展開しています。偶然の一致かもしれませんが、Microsoft Internet Explorerは、HTTP/1.1クライアント標準を実装した最初の主要なブラウザとなった直後に、Webブラウザ市場シェアでNetscape Navigatorを超えました。さらに、標準化プロセス中に定義されたHostヘッダーフィールドなどの個々のHTTP拡張は、現在では普遍的に展開されています。
RESTアーキテクチャスタイルは、現代のWebアーキテクチャの設計と展開を導くのに成功しました。これまで、レガシーWebアプリケーションと並行して段階的かつ断片的に展開されたにもかかわらず、新しい標準の導入によって引き起こされた重大な問題はありません。さらに、新しい標準はWebの堅牢性にプラスの影響を与え、キャッシュ階層やコンテンツ配信ネットワークを通じてユーザーが感じるパフォーマンスを向上させる新しい方法を可能にしました。
6.5 アーキテクチャの教訓
現代のWebアーキテクチャとRESTが指摘した問題から、いくつかの一般的なアーキテクチャの教訓を学ぶことができます。
6.5.1 ネットワークベースのAPIの利点
現代のWebを他のミドルウェア [22] と区別するのは、HTTPをネットワークベースのアプリケーションプログラミングインターフェース(API)として使用する方法です。これは常にそうであったわけではありません。初期のWeb設計では、すべてのクライアントとサーバーのための単一の実装ライブラリとしてCERN libwwwが使用されていました。CERN libwwwは、相互運用可能なWebコンポーネントを構築するためのライブラリベースのAPIを提供していました。
ライブラリベースのAPIは、一連のコードエントリーポイントと関連するシンボル/パラメーターセットを提供し、プログラマーが他の人のコードを使用して、類似システム間の実際のインターフェースを維持する面倒な作業を行うことができるようにします。ただし、プログラマーはそのコードに伴うアーキテクチャと言語の制約に従う必要があります。ここでの前提は、通信のすべての側が同じAPIを使用するため、インターフェースの内部はAPI開発者にとってのみ重要であり、アプリケーション開発者にとっては重要ではないということです。
単一ライブラリのアプローチは1993年に終わりを迎えました。これは、Webの開発に関与する組織の社会的ダイナミクスに合致しなかったためです。NCSAのチームがCERNに比べてはるかに大規模な開発チームでWeb開発のペースを加速させたとき、libwwwのソースは「フォーク」され(別々に維持されるコードベースに分割され)、NCSAの人々がCERNが彼らの改善に追いつくのを待つ必要がなくなりました。同時に、私のような独立した開発者が、CERNのコードでまだサポートされていない言語やプラットフォーム向けのプロトコルライブラリの開発を始めました。Webの設計は、リファレンスプロトコルライブラリの開発から、複数のプラットフォームと実装にわたってWebの望ましいセマンティクスを拡張するネットワークベースのAPIの開発へとシフトしなければなりませんでした。
ネットワークベースのAPIは、アプリケーション間の相互作用のための、定義されたセマンティクスを持つオンザワイヤーの構文です。ネットワークベースのAPIは、ネットワークへの読み書きの必要性以外にはアプリケーションコードに何の制約も課しませんが、インターフェースを介して効果的に伝達できるセマンティクスのセットには制約を課します。良い点として、パフォーマンスはプロトコル設計によってのみ制限され、その設計の特定の実装には依存しません。
ライブラリベースのAPIはプログラマーのために多くのことを行いますが、それによって単一のシステムが必要とするよりもはるかに多くの複雑さと負荷を生み出し、異種ネットワークでの移植性が低く、常にパフォーマンスよりも汎用性が優先されます。副作用として、怠惰な開発(すべてをAPIコードのせいにする)や、通信の他の当事者による非協力的な行動を考慮しないことも引き起こします。
ただし、現代のWebを含むあらゆるアーキテクチャにはさまざまな層が関与していることを覚えておくことが重要です。Webのようなシステムは、複数のネットワークベースのAPI(例:HTTPやFTP)にアクセスするために1つのライブラリAPI(ソケット)を使用しますが、ソケットAPI自体はアプリケーション層の下にあります。同様に、libwwwは、ネットワークベースのAPIにアクセスするためのライブラリベースのAPIに進化した興味深い交雑種であり、他の通信アプリケーションがlibwwwを使用していることを前提とせずに再利用可能なコードを提供します。
これは、CORBA [97] のようなミドルウェアとは対照的です。CORBAはORBを介した通信のみを許可するため、その転送プロトコルであるIIOPは、通信する当事者についてあまりにも多くのことを前提としています。HTTPリクエストメッセージには標準化されたアプリケーションセマンティクスが含まれていますが、IIOPメッセージには含まれていません。IIOPの「Request」トークンは、ORBがそれをルーティングするための方向性のみを提供し、ORB自体が応答するか(例:「LocateRequest」)、オブジェクトによって解釈されるかどうかを決定します。セマンティクスは
オブジェクトキーと操作の組み合わせによって表現され、これはオブジェクト固有であり、すべてのオブジェクトにわたって標準化されていません。 独立した開発者は、同じORBを使用せずにIIOPリクエストと同じビットを生成できますが、ビット自体はCORBA APIとそのインターフェース定義言語(IDL)によって定義されています。それらは、IDLコンパイラによって生成されたUUID、そのIDL操作のシグネチャを反映する構造化されたバイナリコンテンツ、およびIDL仕様に従った返信データ型の定義を必要とします。したがって、セマンティクスはネットワークインターフェース(IIOP)ではなく、オブジェクトのIDL仕様によって定義されます。これが良いことかどうかはアプリケーションによります——分散オブジェクトにとっては必要ですが、Webにとってはそうではありません。
なぜこれが重要なのでしょうか?なぜなら、ネットワーク仲介者が効果的なエージェントとなり得るシステムと、せいぜいルーターとなり得るシステムとを区別するからです。このような違いは、メッセージを単位として解釈するか、ストリームとして解釈するかにも見られます。HTTPでは、受信者または送信者がそれを自分で決定することができます。CORBA IDLでは、まだストリームは許可されていませんが、たとえストリームをサポートするように拡張されたとしても、通信の両側は同じAPIに縛られることになり、それぞれのアプリケーションタイプに最も適したものを自由に使用することはできません。
6.5.2 HTTPはRPCではない
人々はしばしば、HTTPをリモートプロシージャコール(RPC)[23]メカニズムと誤解します。それは単にリクエストとレスポンスが含まれているからです。RPCを他のネットワークベースのアプリケーション通信と区別するのは、リモートマシン上のプロシージャを呼び出すという概念で、プロトコルがプロシージャを識別し、それを固定されたパラメータセットに渡し、同じインターフェースを使用して返信メッセージ内に答えが提供されるのを待つことです。リモートメソッド呼び出し(RMI)は似ていますが、プロシージャはサービスプロシージャではなく、{オブジェクト、メソッド}のタプルとして識別されます。仲介型RMIは、名前サービス間接参照といくつかの他のトリックを追加しますが、インターフェースは基本的に同じです。 HTTPをRPCと区別するのは、構文ではありません。ストリームをパラメータとして使用することで得られる異なる特性でさえありませんが、それは既存のRPCメカニズムがWebに使用できなかった理由を説明するのに役立ちます。HTTPをRPCと大きく異ならせるのは、リクエストが標準的なセマンティクスを持つ汎用インターフェースを使用してリソースに方向付けられ、仲介者によってほぼ同様に解釈できることです。その結果、情報の起源とは独立した変換と間接参照の層を許容するアプリケーションが生まれます。これは、インターネット規模の多組織、無政府的にスケーラブルな情報システムにとって非常に有用です。一方、RPCメカニズムは、ネットワークベースのアプリケーションではなく、言語APIに関して定義されています。
6.5.3 HTTPはトランスポートプロトコルではない
HTTPはトランスポートプロトコルとして設計されていません。それは、リソースの表現を転送および操作することによって、それらのリソースに対するアクションを実行することで、Webアーキテクチャのセマンティクスを反映するメッセージを持つ転送プロトコルです。この非常に単純なインターフェースを使用して幅広い機能を実現することは可能ですが、HTTPセマンティクスが仲介者に対して可視であるためには、インターフェースに従う必要があります。 それが、HTTPがファイアウォールを通過する理由です。最近提案されたHTTPの拡張のほとんどは、WebDAV [60]を除いて、HTTPを他のアプリケーションプロトコルをファイアウォールを通過させる方法として使用しているだけで、これは根本的に誤った考えです。ファイアウォールの目的を無効にするだけでなく、長期的には機能しません。なぜなら、ファイアウォールベンダーは単に追加のプロトコルフィルタリングを実行する必要があるからです。したがって、HTTPの上にこれらの拡張を行うのは意味がありません。なぜなら、その状況でHTTPが達成する唯一のことは、レガシーな構文からオーバーヘッドを追加することだからです。真の
HTTPのアプリケーションは、プロトコルユーザーのアクションをHTTPのセマンティクスで表現できるものにマッピングし、エージェントや仲介者がアプリケーションの知識なしに理解できるネットワークベースのAPIをサービスに対して作成します。
6.5.4 メディアタイプの設計
RESTのアーキテクチャスタイルにおいて特異な側面の一つは、Webアーキテクチャ内のデータ要素の定義に及ぼす影響の度合いです。
6.5.4.1 ネットワークベースシステムにおけるアプリケーション状態
RESTは、部分的な障害が発生しやすいネットワークベースのアプリケーションに対して、シンプルで堅牢なアプリケーションをサポートする期待されるアプリケーション動作のモデルを定義します。しかし、これによってアプリケーション開発者がモデルに違反する機能を導入することを防ぐことはできません。最も頻繁に発生する違反は、アプリケーション状態とステートレスな相互作用に関する制約に関連しています。
アプリケーション状態の誤った配置によるアーキテクチャのミスマッチは、HTTPクッキーに限定されません。ハイパーテキストマークアップ言語(HTML)に「フレーム」が導入されたことにより、同様の混乱が引き起こされました。フレームは、ブラウザウィンドウをサブウィンドウに分割し、それぞれが独自のナビゲーション状態を持つことを可能にします。サブウィンドウ内のリンク選択は通常の遷移と区別がつきませんが、結果として得られるレスポンス表現は、ブラウザアプリケーションのワークスペース全体ではなく、サブウィンドウ内にレンダリングされます。これは、リンクがサブウィンドウ処理を意図した情報の領域を離れない限り問題ありませんが、それが発生すると、ユーザーはあるアプリケーションが別のアプリケーションのサブコンテキスト内に埋め込まれた状態で表示されることになります。
フレームとクッキーの両方において、失敗の原因は、ユーザーエージェントが管理または解釈できない間接的なアプリケーション状態を提供したことです。この情報を主要な表現内に配置し、指定されたリソース領域のハイパーメディアワークスペースを管理する方法をユーザーエージェントに通知する設計であれば、RESTの制約に違反することなく同じタスクを達成し、より良いユーザーインターフェースとキャッシュへの干渉の少ない結果をもたらすことができたでしょう。
6.5.4.2 インクリメンタル処理
レイテンシの削減をアーキテクチャの目標に含めることで、RESTはメディアタイプ(表現のデータ形式)をユーザーが認識するパフォーマンスに応じて区別することができます。サイズ、構造、およびインクリメンタルレンダリングの能力は、表現メディアタイプの転送、レンダリング、および操作におけるレイテンシに影響を与え、システムのパフォーマンスに大きな影響を及ぼす可能性があります。
HTML [18]は、大部分において良好なレイテンシ特性を持つメディアタイプの例です。初期のHTML内の情報は、受信した時点でレンダリングすることができました。なぜなら、HTMLを構成する小さなマークアップタグのセットの標準化された定義内で、すべてのレンダリング情報が早期に利用可能だったからです。しかし、HTMLにはレイテンシに対して十分に設計されていない側面もあります。例としては、ドキュメントのHEAD内に埋め込まれたメタデータの配置があり、これにより、レンダリングエンジンがユーザーに有用な部分を読み取る前に、オプションの情報を転送および処理する必要が生じます [93]。レンダリングサイズのヒントがない埋め込み画像は、画像の最初の数バイト(レイアウトサイズを含む部分)を受信するまで、周囲のHTMLの残りの部分を表示することができません。動的にサイズが決定されるテーブル列は、レンダラーがテーブル全体のサイズを読み取り、決定するまで、上部の表示を開始することができません。また、不正なマークアップ構文の解析に関する緩いルールは、レンダリングエンジンがファイル全体を解析して、1つの重要なマークアップ文字が欠けていることを確認する必要があることが多いです。
6.5.4.3 Java対JavaScript
RESTは、開発者のバランスが異なる場合でも、なぜ一部のメディアタイプがWebアーキテクチャ内で他のものよりも広く採用されているのかを理解するためにも使用できます。
意見は彼らに有利ではありません。JavaアプレットとJavaScriptのケースはその一例です。
JavaTM [45]は、もともとテレビのセットトップボックス内のアプリケーション向けに開発された人気のあるプログラミング言語ですが、Web上で_コードオンデマンド_機能を実装する手段として導入されたときに最初に注目を集めました。
この言語は、所有者である Sun Microsystems, Inc. から莫大なプレスサポートを受け、C++言語に代わるものを求めるソフトウェア開発者から絶賛されましたが、Web内でのコードオンデマンドとしてアプリケーション開発者に広く採用されるには至りませんでした。
Javaが導入されて間もなく、Netscape Communications Corporationの開発者たちは、埋め込み型のコードオンデマンド用に別の言語を作成しました。最初はLiveScriptと呼ばれていましたが、後にマーケティング上の理由でJavaScriptという名前に変更されました(2つの言語はそれ以外にほとんど共通点がありません)[44]。
当初はHTMLに埋め込まれているにもかかわらず、適切なHTML構文と互換性がないと嘲笑されていましたが、JavaScriptの使用は導入以来着実に増加しています。
問題は、なぜWeb上でJavaScriptがJavaよりも成功しているのかということです。
その理由は、言語としての技術的な品質によるものではありません。なぜなら、JavaScriptの構文と実行環境はJavaと比較して貧弱であると見なされているからです。
また、マーケティングによるものでもありません。Sunはその点でNetscapeをはるかに上回る投資を行っており、現在も続けています。
言語の本質的な特性によるものでもありません。なぜなら、Javaは他のすべてのプログラミング領域(スタンドアロンアプリケーション、サーブレットなど)でJavaScriptよりも成功しているからです。
この不一致の理由をよりよく理解するために、REST内での表現メディアタイプとしての特性という観点からJavaを評価する必要があります。
JavaScriptは、Web技術の展開モデルにより適合しています。
言語全体の複雑さや、初心者プログラマーが最初の動作するコードを作成するために必要な初期努力の量という点で、参入障壁がはるかに低いです。
また、JavaScriptは相互作用の可視性に対する影響も少ないです。独立した組織は、HTMLをコピーできるのと同じ方法でJavaScriptのソースコードを読み取り、検証し、コピーできます。
一方、Javaはバイナリパッケージアーカイブとしてダウンロードされるため、ユーザーはJava実行環境内のセキュリティ制限を信頼するしかありません。
同様に、Javaにはセキュアな環境内で許可することが疑わしいと見なされる機能が多く含まれています。その中には、RMIリクエストを元のサーバーに送信する機能も含まれます。RMIは仲介者の可視性をサポートしません。
おそらく、両者の最も重要な違いは、JavaScriptがユーザーが認識する遅延を少なくすることです。
JavaScriptは通常、プライマリ表現の一部としてダウンロードされますが、Javaアプレットは別のリクエストを必要とします。
Javaコードは、バイトコード形式に変換されると、一般的なJavaScriptよりもはるかに大きくなります。
最後に、JavaScriptはHTMLページの残りの部分がダウンロードされている間に実行できますが、Javaはアプリケーションを開始する前にクラスファイルの完全なパッケージをダウンロードしてインストールする必要があります。
したがって、Javaはインクリメンタルレンダリングをサポートしていません。
言語の特性がRESTの制約の背後にある理論と同じように提示されると、現代のWebアーキテクチャ内での技術の振る舞いを評価することがはるかに容易になります。
6.6 まとめ
この章では、ハイパーテキスト転送プロトコル(HTTP)および統一資源識別子(URI)のインターネット標準を作成する際にRESTを適用した経験とそこから学んだ教訓について説明しました。これら2つの仕様は、Web上のすべてのコンポーネント間の相互作用で使用される汎用インターフェースを定義しています。さらに、libwww-perlクライアントライブラリ、Apache HTTPサーバープロジェクト、およびプロトコル標準の他の実装の形でこれらの技術を展開した経験と学んだ教訓についても説明しました。
結論..
私たちの誰もが、心のどこかに、生きる世界、宇宙を作り上げたいという夢を抱いています。
建築家として訓練を受けた私たちにとって、この願いはおそらく人生の中心にあるものです:いつの日か、どこかで、どうにかして、素晴らしく、美しく、息をのむような建物を建て、人々が何世紀にもわたって歩き、夢を見ることができる場所を作り上げるということです。
— Christopher Alexander [3]
インターネットエンジニアリングタスクフォース(IETF)内で、既存のハイパーテキスト転送プロトコル(HTTP/1.0)[19]を定義し、新しい標準であるHTTP/1.1 [42]とUniform Resource Identifiers (URI) [21]の拡張を設計する取り組みの最初に、私はワールドワイドウェブがどのように機能する_べきか_というモデルの必要性を認識しました。この理想化されたウェブアプリケーション内の相互作用のモデルは、Representational State Transfer(REST)アーキテクチャスタイルと呼ばれ、現代のウェブアーキテクチャの基盤となり、既存のアーキテクチャの欠点を特定し、展開前に拡張機能を検証するための指針を提供しました。
RESTは、レイテンシとネットワーク通信を最小化しつつ、コンポーネント実装の独立性とスケーラビリティを最大化することを試みる、アーキテクチャ上の制約の一連のセットです。これは、他のスタイルがコンポーネントセマンティクスに焦点を当てているのに対して、RESTはコネクタセマンティクスに制約を課すことで実現されます。RESTは、インタラクションのキャッシュと再利用、コンポーネントの動的な置換可能性、および仲介者によるアクションの処理を可能にし、インターネットスケールの分散ハイパーメディアシステムのニーズを満たします。
この論文の一部として、情報科学とコンピューター科学の分野に以下の貢献がなされました:
- アーキテクチャスタイルを通じてソフトウェアアーキテクチャを理解するためのフレームワーク。これには、ソフトウェアアーキテクチャを記述するための一貫した用語セットが含まれます。 - ネットワークベースのアプリケーションソフトウェアのアーキテクチャスタイルの分類。これは、分散ハイパーメディアシステムのアーキテクチャに適用されたときに誘発されるアーキテクチャ特性に基づいています。 - REST、分散ハイパーメディアシステムのための新しいアーキテクチャスタイル。 - 現代のワールドワイドウェブのアーキテクチャの設計と展開におけるRESTアーキテクチャスタイルの適用と評価。
現代のウェブは、RESTスタイルのアーキテクチャの一例です。ウェブベースのアプリケーションは、他のスタイルのインタラクションへのアクセスを含むことができますが、そのプロトコルとパフォーマンスの中心的な焦点は分散ハイパーメディアです。RESTは、インターネットスケールの分散ハイパーメディアインタラクションにとって不可欠と見なされるアーキテクチャの部分のみを詳細に説明しています。既存のプロトコルがコンポーネントインタラクションの潜在的なセマンティクスのすべてを表現できていない場合や、構文の詳細がアーキテクチャの能力を変えることなくより効率的な形式に置き換えられる場合、ウェブアーキテクチャの改善の余地が見られます。同様に、提案された拡張機能は、アーキテクチャに適合するかどうかをRESTと比較することができます。適合しない場合、その機能をより適切なアーキテクチャスタイルを持つ並行システムにリダイレクトする方が効率的です。
理想的な世界では、ソフトウェアシステムの実装はその設計と完全に一致します。現代のウェブアーキテクチャの一部の特徴は、RESTにおける設計基準と完全に一致しています。例えば、URI [21]をリソース識別子として使用し、インターネットメディアタイプ [48]を使用して表現データ形式を識別することなどです。しかし、アーキテクチャ設計に反して存在する現代のウェブプロトコルの側面もあります。これは、失敗したレガシー実験(ただし、後方互換性のために保持する必要があるもの)や、アーキテクチャスタイルを認識していない開発者によって展開された拡張機能によるものです。RESTは、新機能の開発と評価だけでなく、
破損した機能の特定と理解。
World Wide Webは、間違いなく世界最大の分散アプリケーションです。
Webの基盤となる主要なアーキテクチャ原則を理解することは、その技術的な成功を説明するのに役立ち、他の分散アプリケーション、特に同じまたは類似の相互作用方法に適したアプリケーションの改善につながる可能性があります。RESTは、現代のWebのソフトウェアアーキテクチャの背後にある理論的根拠と、ソフトウェア工学の原則を実際のソフトウェアシステムの設計と評価に体系的に適用する方法に関する重要な教訓の両方を提供します。
ネットワークベースのアプリケーションでは、システムのパフォーマンスはネットワーク通信に大きく依存します。分散ハイパーメディアシステムの場合、コンポーネント間の相互作用は、計算集約的なタスクではなく、大規模なデータ転送で構成されます。RESTスタイルは、これらのニーズに応えて開発されました。リソースと表現の汎用コネクタインターフェースに焦点を当てることで、中間処理、キャッシュ、コンポーネントの代替性が可能になり、その結果、Webベースのアプリケーションは1994年の1日あたり100,000リクエストから1999年の1日あたり600,000,000リクエストまでスケールすることができました。
RESTアーキテクチャスタイルは、HTTP/1.0 [19]およびHTTP/1.1 [42]標準の6年間の開発、URI [21]および相対URL [40]標準の詳細化、そして現代のWebアーキテクチャ内で数十の独立して開発された商用グレードのソフトウェアシステムの成功した展開を通じて検証されています。これは、設計ガイダンスのモデルとして、またWebプロトコルへのアーキテクチャ拡張の厳密なテストとして機能してきました。
今後の作業は、HTTP/1.xプロトコルファミリーの代替となる開発に向けたアーキテクチャガイダンスの拡張に焦点を当てます。より効率的なトークン化構文を使用しますが、RESTによって特定された望ましい特性を失うことなく進めます。RESTの原則と多くの共通点を持つワイヤレスデバイスのニーズは、アプリケーションレベルのプロトコル設計とアクティブな仲介者を含むアーキテクチャのさらなる強化を動機付けるでしょう。また、可変リクエスト優先度、差別化されたサービス品質、およびブロードキャストオーディオやビデオソースによって生成されるような連続データストリームで構成される表現を考慮したRESTの拡張にも関心が寄せられています。
参考文献
- G. D. Abowd, R. Allen, および D. Garlan. ソフトウェアアーキテクチャの記述を理解するためのスタイルの形式化. ACM Transactions on Software Engineering and Methodology , 4(4), 1995年10月, pp. 319–364. 短縮版は以下にも掲載: スタイルを使用してソフトウェアアーキテクチャの記述を理解する. In Proceedings of the First ACM SIGSOFT Symposium on the Foundations of Software Engineering (SIGSOFT‘93) , ロサンゼルス, CA, 1993年12月, pp. 9–20.
- Adobe Systems Inc. PostScript Language Reference Manual. Addison-Wesley Publishing Company, マサチューセッツ州レディング, 1985年.
- C. Alexander. The Timeless Way of Building. オックスフォード大学出版局, ニューヨーク, 1979年.
- C. Alexander, S. Ishikawa, M. Silverstein, M. Jacobson, I. Fiksdahl-King, および S. Angel. A Pattern Language. オックスフォード大学出版局, ニューヨーク, 1977年.
- R. Allen および D. Garlan. アーキテクチャ接続の形式的基礎. ACM Transactions on Software Engineering and Methodology , 6(3), 1997年7月. 短縮版は以下にも掲載: アーキテクチャ接続の形式化. In Proceedings of the 16th International Conference on Software Engineering , ソレント, イタリア, 1994年5月, pp. 71–80. また以下のようにも掲載: 定義/使用を超えて: アーキテクチャ相互接続. In Proceedings of the ACM Interface Definition Language Workshop , ポートランド, オレゴン州, SIGPLAN Notices , 29(8), 1994年8月.
- G. Andrews. 分散プログラムにおけるプロセス相互作用のパラダイム. ACM Computing Surveys , 23(1), 1991年3月, pp. 49–90.
- F. Anklesaria, 他. インターネットGopherプロトコル (分散ドキュメント検索 および取得プロトコル). Internet RFC 1436 , 1993年3月.
- D. J. Barrett, L. A. Clarke, P. L. Tarr, A. E. Wise. イベントベースの ソフトウェア統合のためのフレームワーク. ACM Transactions on Software Engineering and Methodology , 5(4), 1996年10月, pp. 378–421.
- L. Bass, P. Clements, および R. Kazman. Software Architecture in Practice. Addison Wesley, マサチューセッツ州レディング, 1998年.
-
D. Batory, L. Coglianese, S. Shafer, および W. Tracz. ADAGE航空電子参照 アーキテクチャ. In Proceedings of AIAA Computing in Aerospace 10 , サンアントニオ, 1995年.
- T. Berners-Lee, R. Cailliau, および J.-F. Groff. World Wide Web. 3rd Joint European Networking Conference で配布されたフライヤー, インスブルック, オーストリア, 1992年5月.
- T. Berners-Lee, R. Cailliau, J.-F. Groff, および B. Pollermann. World-Wide Web: 情報宇宙. Electronic Networking: Research, Applications and Policy , 2(1), Meckler Publishing, ウェストポート, CT, 1992年春, pp. 52–58.
- T. Berners-Lee および R. Cailliau. World-Wide Web. In Proceedings of Computing in High Energy Physics 92 , アヌシー, フランス, 1992年9月23–27日.
- T. Berners-Lee, R. Cailliau, C. Barker, および J.-F. Groff. W3プロジェクト: さまざまな デザインノート. ウェブ上で公開, 1992年11月. 以下にアーカイブ <http://www.w3.org/History/19921103-hypertext/hypertext/WWW/ WorkingNotes/Overview.html>, 2000年9月.
- T. Berners-Lee. WWWにおけるユニバーサルリソース識別子. Internet RFC 1630 , 1994年6月.
- T. Berners-Lee, R. Cailliau, A. Luotonen, H. Frystyk Nielsen, および A. Secret. ワールドワイドウェブ. Communications of the ACM , 37(8), 1994年8月, pp. 76–82.
- T. Berners-Lee, L. Masinter, および M. McCahill. ユニフォームリソースロケータ (URL). Internet RFC 1738 , 1994年12月.
- T. Berners-Lee および D. Connolly. ハイパーテキストマークアップ言語 — 2.0. Internet RFC 1866 , 1995年11月.
- T. Berners-Lee, R. T. Fielding, および H. F. Nielsen. ハイパーテキスト転送プロトコル — HTTP/1.0. Internet RFC 1945 , 1996年5月.
- T. Berners-Lee. WWW: 過去, 現在, 未来. IEEE Computer , 29(10), 1996年10月, pp. 69–77.
-
T. Berners-Lee, R. T. Fielding, および L. Masinter. ユニフォームリソース識別子 (URI): 汎用構文. Internet RFC 2396 , 1998年8月.
- P. バーンスタイン。ミドルウェア:分散システムサービスのモデル。
Communications of the ACM 、1996年2月、pp. 86–98。 - A. D. ビレルとB. J. ネルソン。リモートプロシージャコールの実装。
ACM Transactions on Computer Systems 、2巻、1984年1月、pp. 39–59。 -
M. ボアソン。ソフトウェアアーキテクチャの芸術性。
IEEE Software 、12(6)、1995年11月、pp. 13–16。 - G. ブーチ。オブジェクト指向開発。
IEEE Transactions on Software Engineering 、12(2)、1986年2月、pp. 211–221。 - C. ブルックス、M. S. メイザー、S. ミークス、J. ミラー。HTTPストリームトランスデューサとしてのアプリケーション固有のプロキシサーバー。
第四回国際ワールドワイドウェブ会議議事録 、マサチューセッツ州ボストン、1995年12月、pp. 539–548。 - F. ブッシュマンとR. ムニエ。パターンのシステム。コプリエンとシュミット(編)、
Pattern Languages of Program Design 、Addison-Wesley、1995年、pp. 325–343。 - F. ブッシュマン、R. ムニエ、H. ローネルト、P. ゾンマーラッド、M. スタル。
Pattern-oriented Software Architecture: パターンのシステム 。John Wiley & Sons Ltd.、イギリス、1996年。 - M. R. カガン。HP SoftBench環境:新世代ソフトウェアツールのアーキテクチャ。
Hewlett-Packard Journal 、41(3)、1990年6月、pp. 36–47。 - J. R. キャメロン。JSDの概要。
IEEE Transactions on Software Engineering 、12(2)、1986年2月、pp. 222–240。 - R. S. チンとS. T. チャンソン。分散オブジェクトベースのプログラミングシステム。
ACM Computing Surveys 、23(1)、1991年3月、pp. 91–124。 - D. D. クラークとD. L. テネンハウス。新世代プロトコルのアーキテクチャ的考察。
ACM SIGCOMM‘90シンポジウム議事録 、ペンシルベニア州フィラデルフィア、1990年9月、pp. 200–208。 - J. O. コプリエンとD. C. シュミット(編)。
Pattern Languages of Program Design 。Addison-Wesley、マサチューセッツ州リーディング、1995年。 - J. O. コプリエン。イディオムとパターンとしてのアーキテクチャ文献。
IEEE Software 、14(1)、1997年1月、pp. 36–42。 - E. M. ダショフィー、N. メドヴィドビッチ、R. N. テイラー。オフ・ザ・シェルフのミドルウェアを使用した分散ソフトウェアアーキテクチャにおけるコネクタの実装。
1999年国際ソフトウェアエンジニアリング会議議事録 、ロサンゼルス、1999年5月16–22日、pp. 3–12。 - F. デイビス他。
WAIS Interface Protocol Prototype Functional Specification (v.1.5) 。Thinking Machines Corporation、1990年4月。 -
F. デレマーとH. H. クロン。大規模プログラミング対小規模プログラミング。
IEEE Transactions on Software Engineering 、SE-2(2)、1976年6月、pp. 80–86。 - E. ディ・ニットとD. ローゼンブラム。ミドルウェアインフラストラクチャによって誘発されるアーキテクチャスタイルを指定するためのADLの活用。
1999年国際ソフトウェアエンジニアリング会議議事録 、ロサンゼルス、1999年5月16–22日、pp. 13–22。 - R. T. フィールディング。分散ハイパーテキストインフラストラクチャの維持:MOMspiderのウェブへようこそ。
Computer Networks and ISDN Systems 、27(2)、1994年11月、pp. 193–204。 - R. T. フィールディング。相対的なユニフォームリソースロケーター。
Internet RFC 1808 、1995年6月。 - R. T. フィールディング、E. J. ホワイトヘッドJr.、K. M. アンダーソン、G. ボルサー、P. オレイジー、R. N. テイラー。複雑な情報製品のウェブベース開発。
Communications of the ACM 、41(8)、1998年8月、pp. 84–92。 - R. T. フィールディング、J. ゲティス、J. C. モーグル、H. F. ニールセン、L. マシンター、P. リーチ、T. バーナーズ・リー。ハイパーテキスト転送プロトコル — HTTP/1.1。
Internet RFC 2616 、1999年6月。[RFC 2068、1997年1月を廃止。] - R. T. フィールディングとR. N. テイラー。近代ウェブアーキテクチャの原則に基づいた設計。
2000年国際ソフトウェアエンジニアリング会議 (ICSE 2000) 議事録 、アイルランド、リムリック、2000年6月、pp. 407–416。 - D. フラナガン。
JavaScript: ザ・ディフィニティブガイド、第3版 。O’Reilly & Associates、カリフォルニア州セバストポル、1998年。 -
D. フラナガン。
JavaTM インナッツシェル、第3版 。O’Reilly & Associates、カリフォルニア州セバストポル、1999年。 - J. Franks, P. Hallam-Baker, J. Hostetler, S. Lawrence, P. Leach, A. Luotonen, E. Sink, and L. Stewart. HTTP認証: 基本およびダイジェストアクセス認証. インターネット RFC 2617 , 1999年6月.
- N. Freed and N. Borenstein. 多目的インターネットメール拡張 (MIME) パート1: インターネットメッセージ本体の形式. インターネット RFC 2045 , 1996年11月.
- N. Freed, J. Klensin, and J. Postel. 多目的インターネットメール拡張 (MIME) パート4: 登録手続き. インターネット RFC 2048 , 1996年11月.
- M. Fridrich and W. Older. Helix: XMS分散ファイルシステムのアーキテクチャ. IEEE Software , 2, 1985年5月, pp. 21–29.
-
A. Fuggetta, G. P. Picco, and G. Vigna. コードモビリティの理解. IEEEソフトウェアエンジニアリングトランザクション , 24(5), 1998年5月, pp. 342–361.
- E. Gamma, R. Helm, R. Johnson, and J. Vlissides. デザインパターン: 再利用可能なオブジェクト指向ソフトウェアの要素. Addison-Wesley, Reading, Mass., 1995.
- D. Garlan and E. Ilias. 統合環境における低コストで適応可能なツール統合ポリシー. ACM SIGSOFT ‘90: 第4回ソフトウェア開発環境シンポジウム議事録 , 1990年12月, pp. 1–10.
- D. Garlan and M. Shaw. ソフトウェアアーキテクチャ入門. Ambriola & Tortola (編), ソフトウェアエンジニアリング & 知識エンジニアリングの進展 , vol. II, World Scientific Pub Co., Singapore, 1993, pp. 1–39.
- D. Garlan, R. Allen, and J. Ockerbloom. アーキテクチャ設計環境におけるスタイルの活用. 第2回ACM SIGSOFTソフトウェアエンジニアリング基礎シンポジウム (SIGSOFT‘94) 議事録 , New Orleans, 1994年12月, pp. 175–188.
- D. Garlan and D. E. Perry. ソフトウェアアーキテクチャ特集号への導入. IEEEソフトウェアエンジニアリングトランザクション , 21(4), 1995年4月, pp. 269–274.
- D. Garlan, R. Allen, and J. Ockerbloom. アーキテクチャのミスマッチ、または、なぜ既存の部品からシステムを構築するのが難しいのか. 第17回国際ソフトウェアエンジニアリング会議議事録 , Seattle, WA, 1995年. また、以下のようにも登場: アーキテクチャのミスマッチ: なぜ再利用がそんなに難しいのか. IEEE Software , 12(6), 1995年11月, pp. 17–26.
- D. Garlan, R. Monroe, and D. Wile. ACME: アーキテクチャ記述言語. CASCON‘ 97議事録 , 1997年11月.
- C. Ghezzi, M. Jazayeri, and D. Mandrioli. ソフトウェアエンジニアリングの基礎. Prentice-Hall, 1991.
- S. Glassman. World Wide Webのためのキャッシングリレー. コンピュータネットワークとISDNシステム , 27(2), 1994年11月, pp. 165–173.
- Y. Goland, E. J. Whitehead, Jr., A. Faizi, S. Carter, and D. Jensen. 分散オーサリングのためのHTTP拡張 — WEBDAV. インターネット RFC 2518 , 1999年2月.
- K. Grønbaek and R. H. Trigg. Dexterベースのハイパーメディアシステムの設計課題. ACMコミュニケーションズ , 37(2), 1994年2月, pp. 41–49.
-
B. Hayes-Roth, K. Pfleger, P. Lalanda, P. Morignot, and M. Balabanovic. 適応型知能システムのためのドメイン固有ソフトウェアアーキテクチャ. IEEEソフトウェアエンジニアリングトランザクション , 21(4), 1995年4月, pp. 288–301.
- J. Heidemann, K. Obraczka, and J. Touch. 複数のトランスポートプロトコルを介したHTTPのパフォーマンスモデリング. IEEE/ACMネットワーキングトランザクション , 5(5), 1997年10月, pp. 616–630.
- K. Holtman and A. Mutz. HTTPにおける透過的コンテンツネゴシエーション. インターネット RFC 2295 , 1998年3月.
- P. Inverardi and A. L. Wolf. 化学的抽象機械モデルを使用したソフトウェアアーキテクチャの形式的仕様と分析. IEEEソフトウェアエンジニアリングトランザクション , 21(4), 1995年4月, pp. 373–386.
- ISO/IEC JTC1/SC21/WG7. オープン分散処理の参照モデル. ITU-T X.901: ISO/IEC 10746-1, 1995年6月7日.
-
M. Jackson. 問題、方法、および専門化. IEEE Software , 11(6), [ソフトウェアエンジニアリングジャーナルからの抜粋], 1994年11月. pp. 57–62.
- R. Kazman, L. Bass, G. Abowd, M. Webb. SAAM: ソフトウェアアーキテクチャのプロパティを分析する方法. 第16回国際ソフトウェアエンジニアリング会議(ICSE)議事録, ソレント, イタリア, 1994年5月, pp. 81–90.
- R. Kazman, M. Barbacci, M. Klein, S. J. Carrière, S. G. Woods. アーキテクチャトレードオフ分析の実行経験. 1999年国際ソフトウェアエンジニアリング会議議事録, ロサンゼルス, 1999年5月16–22日, pp. 54–63.
- N. L. Kerth, W. Cunningham. パターンを利用してアーキテクチャビジョンを改善する. IEEEソフトウェア, 14(1), 1997年1月, pp. 53–59.
- R. Khare, S. Lawrence. HTTP/1.1内でのTLSへのアップグレード. インターネットRFC 2817, 2000年5月.
- G. E. Krasner, S. T. Pope. Smalltalk-80におけるModel-View-Controllerユーザーインターフェースパラダイムの使用法のクックブック. オブジェクト指向プログラミングジャーナル, 1(3), 1988年8月–9月, pp. 26–49.
- D. Kristol, L. Montulli. HTTP状態管理メカニズム. インターネットRFC 2109, 1997年2月.
- P. B. Kruchten. アーキテクチャの4+1ビューモデル. IEEEソフトウェア, 12(6), 1995年11月, pp. 42–50.
-
D. Le Métayer. グラフ文法を用いたソフトウェアアーキテクチャスタイルの記述. IEEEソフトウェアエンジニアリングトランザクション, 24(7), 1998年7月, pp. 521–533.
- W. C. Loerke. 建築におけるスタイルについて. F. Wilson, 建築: 基本的な問題, Van Nostrand Reinhold, ニューヨーク, 1990, pp. 203–218.
- D. C. Luckham, J. J. Kenney, L. M. Augustin, J. Vera, D. Bryan, W. Mann. Rapideを使用したシステムアーキテクチャの仕様と分析. IEEEソフトウェアエンジニアリングトランザクション, 21(4), 1995年4月, pp. 336–355.
- D. C. Luckham, J. Vera. イベントベースのアーキテクチャ定義言語. IEEEソフトウェアエンジニアリングトランザクション, 21(9), 1995年9月, pp. 717–734.
- A. Luotonen, K. Altis. ワールドワイドウェブプロキシ. コンピュータネットワークとISDNシステム, 27(2), 1994年11月, pp. 147–154.
- P. Maes. 計算的リフレクションの概念と実験. OOPSLA ‘87議事録, オーランド, フロリダ, 1987年10月, pp. 147–155.
- J. Magee, N. Dulay, S. Eisenbach, J. Kramer. 分散ソフトウェアアーキテクチャの仕様. 第5回欧州ソフトウェアエンジニアリング会議(ESEC’95)議事録, シッチェス, スペイン, 1995年9月, pp. 137–153.
- J. Magee, J. Kramer. ソフトウェアアーキテクチャにおける動的構造. 第4回ACM SIGSOFTソフトウェアエンジニアリング基礎シンポジウム(SIGSOFT’96)議事録, サンフランシスコ, 1996年10月, pp. 3–14.
- F. Manola. Webオブジェクトモデルの技術. IEEEインターネットコンピューティング, 3(1), 1999年1月–2月, pp. 38–47.
- H. Maurer. HyperWave: 次世代Webソリューション. Addison-Wesley, ハーロウ, イングランド, 1996.
- M. J. Maybee, D. H. Heimbigner, L. J. Osterweil. 分散システムにおける多言語相互運用性: 経験報告. 第18回国際ソフトウェアエンジニアリング会議議事録, ベルリン, ドイツ, 1996年3月.
- N. Medvidovic, R. N. Taylor. アーキテクチャ記述言語を分類および比較するためのフレームワーク. 第6回欧州ソフトウェアエンジニアリング会議および第5回ACM SIGSOFTソフトウェアエンジニアリング基礎シンポジウム議事録, チューリッヒ, スイス, 1997年9月, pp. 60–76.
- N. Medvidovic. アーキテクチャベースの仕様時ソフトウェア進化. 博士論文, カリフォルニア大学アーバイン校, 1998年12月.
- N. Medvidovic, D. S. Rosenblum, R. N. Taylor. アーキテクチャベースのソフトウェア開発と進化のための言語と環境. 1999年国際ソフトウェアエンジニアリング会議議事録, ロサンゼルス, 1999年5月16–22日, pp. 44–53.
- A. Mockus, R. T. Fielding, J. Herbsleb. オープンソースソフトウェア開発のケーススタディ: Apacheサーバー. 2000年国際会議議事録.
_ソフトウェアエンジニアリング会議 (ICSE 2000)_ 、リムリック、アイルランド、2000年6月、pp. 263–272。
90. J. Mogul、R. Fielding、J. Gettys、H. Frystyk。HTTPバージョン番号の使用と解釈。_インターネットRFC 2145_、1997年5月。
91. R. T. Monroe、A. Kompanek、R. Melton、D. Garlan。アーキテクチャスタイル、デザインパターン、オブジェクト。_IEEEソフトウェア_、14(1)、1997年1月、pp. 43–52。
92. M. Moriconi、X. Qian、R. A. Riemenscheider。正しいアーキテクチャのリファインメント。_IEEEソフトウェアエンジニアリングトランザクション_、21(4)、1995年4月、pp. 356–372。
93. H. F. Nielsen、J. Gettys、A. Baird-Smith、E. Prud'hommeaux、H. Lie、C. Lilley。HTTP/1.1、CSS1、PNGのネットワークパフォーマンスへの影響。_ACM SIGCOMM ’97会議録_、カンヌ、フランス、1997年9月。
94. H. F. Nielsen、P. Leach、S. Lawrence。HTTP拡張フレームワーク、_インターネットRFC 2774_、2000年2月。
95. H. Penny Nii。ブラックボードシステム。_AIマガジン_、7(3):38–53および7(4):82–107、1986年。
96. オブジェクト管理グループ。_オブジェクト管理アーキテクチャガイド、Rev. 3.0_。Soley & Stone(編)、ニューヨーク:J. Wiley、第3版、1995年。
97. オブジェクト管理グループ。_共通オブジェクト要求ブローカー:アーキテクチャと仕様 (CORBA 2.1)_。<http://www.omg.org/>、1997年8月。
98. P. Oreizy、N. Medvidovic、R. N. Taylor。アーキテクチャベースのランタイムソフトウェア進化。_1998年国際ソフトウェアエンジニアリング会議_、京都、日本、1998年4月。
99. P. Oreizy。分散型ソフトウェア進化。未発表原稿(フェーズII調査論文)、1998年12月。
100. V. N. Padmanabhan、J. C. Mogul。HTTPレイテンシの改善。_コンピュータネットワークとISDNシステム_、28、1995年12月、pp. 25–35。
101. D. L. Parnas。設計方法論における情報配布の側面。_IFIP会議71会議録_、リュブリャナ、1971年8月、pp. 339–344。
102. D. L. Parnas。システムをモジュールに分解するための基準について。_ACMコミュニケーション_、15(12)、1972年12月、pp. 1053–1058。
103. D. L. Parnas。拡張と縮小が容易なソフトウェアの設計。_IEEEソフトウェアエンジニアリングトランザクション_、SE-5(3)、1979年3月。
104. D. L. Parnas、P. C. Clements、D. M. Weiss。複雑なシステムのモジュール構造。_IEEEソフトウェアエンジニアリングトランザクション_、SE-11(3)、1985年、pp. 259–266。
105. D. E. Perry、A. L. Wolf。ソフトウェアアーキテクチャ研究の基盤。_ACM SIGSOFTソフトウェアエンジニアリングノート_、17(4)、1992年10月、pp. 40–52。
106. J. Postel、J. Reynolds。TELNETプロトコル仕様。_インターネットSTD 8、RFC 854_、1983年5月。
107. J. Postel、J. Reynolds。ファイル転送プロトコル。_インターネットSTD 9、RFC 959_、1985年10月。
108. D. Pountain、C. Szyperski。拡張可能なソフトウェアシステム。_Byte_、1994年5月、pp. 57–62。
109. R. Prieto-Diaz、J. M. Neighbors。モジュール相互接続言語。_システムとソフトウェアジャーナル_、6(4)、1986年11月、pp. 307–334。
110. J. M. Purtilo。Polylithソフトウェアバス。_ACMプログラミング言語とシステムトランザクション_、16(1)、1994年1月、pp. 151–174。
111. M. Python。建築家のスケッチ。_モンティ・パイソンの空飛ぶサーカスTVショー、エピソード17_、1970年9月。トランスクリプトは<http://www.stone-dead.asn.au/sketches/architec.htm>。
112. J. Rasure、M. Young。画像処理とソフトウェア開発のためのオープン環境。_1992年SPIE/IS&T電子イメージングシンポジウム会議録_、Vol. 1659、1992年2月。
113. S. P. Reiss。Field環境におけるメッセージパッシングを使用したツールの接続。_IEEEソフトウェア_、7(4)、1990年7月、pp. 57–67。
114. D. S. Rosenblum、A. L. Wolf。インターネット規模のイベント観測と通知のための設計フレームワーク。_第6回欧州ソフトウェアエンジニアリング会議および第5回ACM SIGSOFTソフトウェア基礎シンポジウム会議録_、チューリッヒ、スイス、1997年9月、pp. 344–360。
- R. Sandberg, D. Goldberg, S. Kleiman, D. Walsh, および B. Lyon. Sun ネットワークファイルシステムの設計と実装. Usenix カンファレンス議事録 , 1985年6月, pp. 119–130.
- M. Shapiro. 分散システムにおける構造とカプセル化:プロキシ原理. 第6回分散コンピューティングシステム国際会議議事録 , ケンブリッジ, MA, 1986年5月, pp. 198–204.
- M. Shaw. ソフトウェアシステムのためのより高レベルの抽象化に向けて. データ & ナレッジエンジニアリング , 5, 1990年, pp. 119–128.
- M. Shaw, R. DeLine, D. V. Klein, T. L. Ross, D. M. Young, および G. Zelesnick. ソフトウェアアーキテクチャのための抽象化とそれらをサポートするツール. IEEE ソフトウェアエンジニアリングトランザクション , 21(4), 1995年4月, pp. 314–335.
- M. Shaw. アーキテクチャ設計スタイルの比較. IEEE ソフトウェア , 12(6), 1995年11月, pp. 27–41.
- M. Shaw. ソフトウェアアーキテクチャのためのいくつかのパターン. Vlissides, Coplien & Kerth (編), プログラムデザインパターン言語, 第2巻 , Addison-Wesley, 1996年, pp. 255–269.
- M. Shaw および D. Garlan. ソフトウェアアーキテクチャ:新興分野の視点 . Prentice-Hall, 1996年.
- M. Shaw および P. Clements. ボックスロジーのフィールドガイド:ソフトウェアシステムのアーキテクチャスタイルの暫定分類. 第21回年次国際コンピュータソフトウェアおよびアプリケーション会議 (COMPSAC‘97) 議事録 , ワシントンD.C., 1997年8月, pp. 6–13.
- A. Sinha. クライアントサーバーコンピューティング. ACM コミュニケーションズ , 35(7), 1992年7月, pp. 77–98.
- K. Sollins および L. Masinter. Uniform Resource Names の機能要件. インターネット RFC 1737 , 1994年12月.
- S. E. Spero. HTTP パフォーマンス問題の分析. ウェブ上で公開, http://metalab.unc.edu/mdma-release/http-prob.html, 1994年.
- K. J. Sullivan および D. Notkin. 環境統合とソフトウェア進化の調和. ACM ソフトウェアエンジニアリングおよび方法論トランザクション , 1(3), 1992年7月, pp. 229–268.
-
A. S. Tanenbaum および R. van Renesse. 分散オペレーティングシステム. ACM コンピューティングサーベイ , 17(4), 1985年12月, pp. 419–470.
- R. N. Taylor, N. Medvidovic, K. M. Anderson, E. J. Whitehead Jr., J. E. Robbins, K. A. Nies, P. Oreizy, および D. L. Dubrow. GUI ソフトウェアのためのコンポーネントおよびメッセージベースのアーキテクチャスタイル. IEEE ソフトウェアエンジニアリングトランザクション , 22(6), 1996年6月, pp. 390–406.
- W. Tephenhart および J. J. Cusick. 統一オブジェクトトポロジー. IEEE ソフトウェア , 14(1), 1997年1月, pp. 31–35.
- W. Tracz. DSSA(ドメイン固有ソフトウェアアーキテクチャ)教育例. ソフトウェアエンジニアリングノート , 20(3), 1995年7月, pp. 49–62.
- A. Umar. オブジェクト指向クライアント/サーバーインターネット環境 . Prentice Hall PTR, 1997年.
- S. Vestal. MetaH プログラマーズマニュアル, バージョン 1.09. テクニカルレポート , ハネウェルテクノロジーセンター, 1996年4月.
- J. Waldo, G. Wyant, A. Wollrath, および S. Kendall. 分散コンピューティングに関するノート. テクニカルレポート SMLI TR-94-29 , Sun Microsystems Laboratories, Inc., 1994年11月.
- L. Wall, T. Christiansen, および R. L. Schwartz. プログラミングPerl, 第2版 . O’Reilly & Associates, 1996年.
- E. J. Whitehead, Jr., R. T. Fielding, および K. M. Anderson. WWW とリンクサーバーテクノロジーの融合:一つのアプローチ. 第2回オープンハイパーメディアシステムワークショップ, ハイパーテキスト’96 議事録 , ワシントンD.C., 1996年3月, pp. 81–86.
- A. Wolman, G. Voelker, N. Sharma, N. Cardwell, M. Brown, T. Landray, D. Pinnel, A. Karlin, および H. Levy. Web オブジェクトの共有とキャッシングに基づく組織分析. 第2回 USENIX インターネット技術とシステム会議 (USITS) 議事録 , 1999年10月.
-
W. Zimmer. デザインパターン間の関係. Coplien および Schmidt (編), プログラムデザインパターン言語 , Addison-Wesley, 1995年, pp. 345–364.
- H. Zimmerman. OSI参照モデル — 開放型システム相互接続のためのISOアーキテクチャモデル. IEEE Transactions on Communications , 28, Apr. 1980, pp. 425–432.